
Idempotency in software: Designing systems where you can safely retry

Context
Do you want retries to be routine or roulette.
This is not history. It is the situation you face every day. A response can vanish after the work succeeded. The absence of a reply does not mean the absence of a side effect.
By side effect I mean a change you cannot easily undo, like charging a card or sending an email. When the response is lost, the side effect can still be real.
The aha moment is simple. A timeout tells you nothing about state. It only tells you the network failed to answer. That gap is where duplicate charges and duplicate orders are born.
Think of it like mailing a receipt in a different envelope than the purchase. One can arrive without the other. You need a way to resend the receipt without charging again.
Idempotency exists to close that gap. It lets you retry without inventing extra work.
In math, idempotent means f(f(x)) = f(x). Apply it twice and you get the same result after the first. In software, the result is not a return value, it is the state you commit and the side effects you emit.
Decide which operations must survive retries, then name their boundaries before you ship.
The problem
Retries are ambiguous. You send a request, the server acts, and the response disappears. The client cannot know if the operation happened.
If you retry a non idempotent operation, you multiply side effects. Payments, orders, emails, events, and rows can double without anyone intending it. That is how small outages become real damage.
Fix this with design choices that make duplicates harmless, not with heroic manual recovery.
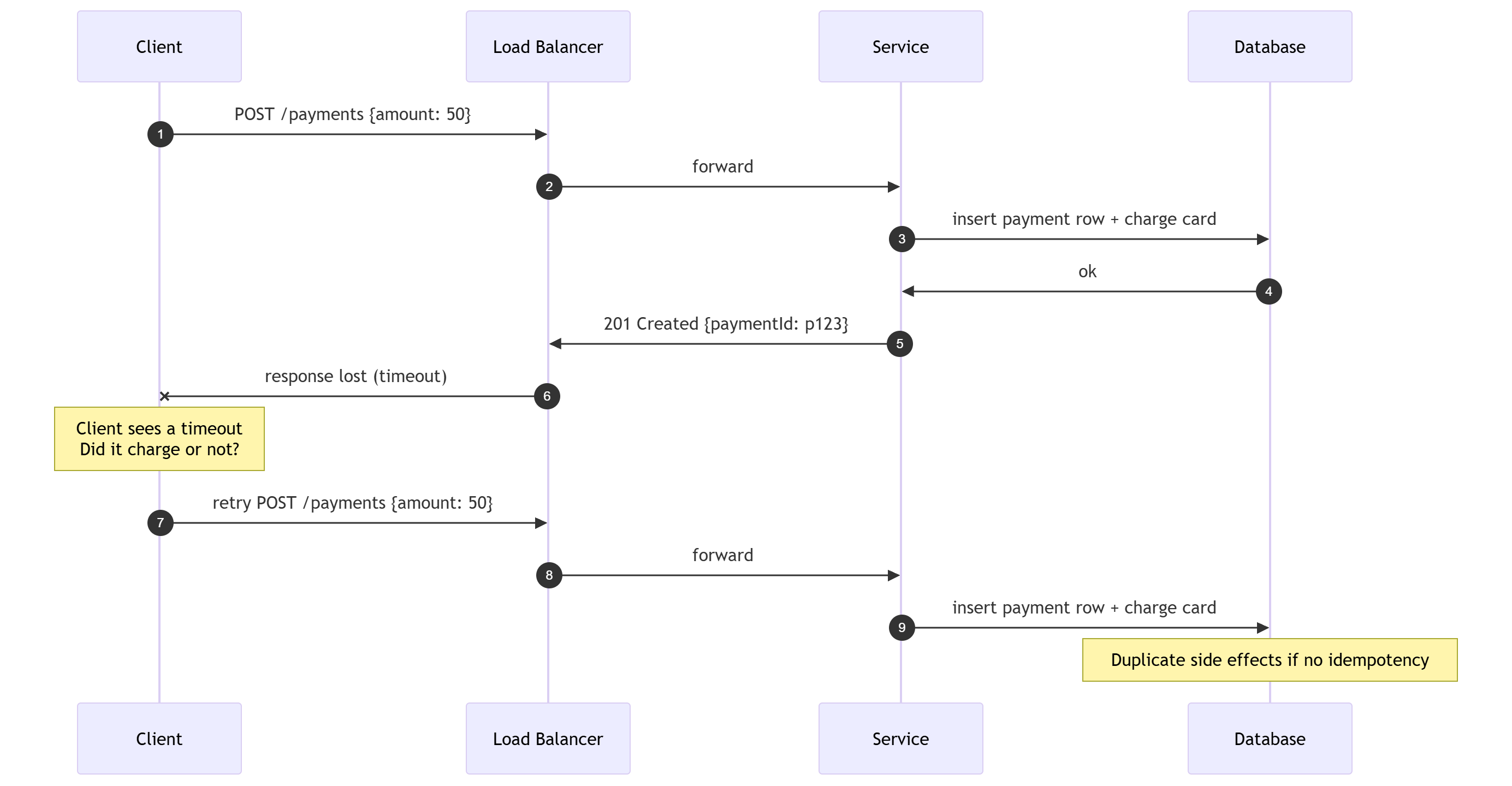
Design retries so the second run is boring.
Constraints and tradeoffs
Networks are unreliable. Brokers deliver at least once because loss is worse than duplicates in many systems. Exactly once across side effects is rare and expensive. At least once means you must expect duplicates, not hope they do not happen. It is common because it favors availability over perfect delivery.
“A message broker should ideally deliver each message only once, but guaranteeing exactly-once messaging is usually too costly.”
- Chris Richardson, Microservices Patterns
So you trade strict delivery guarantees for resilience, and you offset that trade with idempotent handling. That is the practical bargain you must accept.
Pick the guarantee you can own, then engineer for idempotency.
Quote anchor from the Quotes collection
“Make the change easy, then make the easy change.”
- Kent Beck
Idempotency follows this sequencing. First, create a safe dedupe boundary that makes retries predictable. Then simplify handlers and retry policies on top of that stable boundary.
The core model
Idempotency means repeated execution lands on the same final state. Not safe, but convergent toward a target.
Here is a concrete example. If you set OrderStatus to PAID twice, the order is still PAID. If you add 1 to a counter twice, you get a different result, so it is not idempotent.
Got it. Now make it precise. Ask yourself a simple question: if I run this twice, what changes.
Three traps matter.
Intended effect is about state, not about the response. Two retries can return different timestamps and still be idempotent if state converges.
Idempotent is not safe. Safe means no state change. Idempotent means state changes that converge. GET is safe. PUT can be idempotent and still change state.
Idempotent is not no duplicates anywhere. Duplicates can exist at the transport layer. Idempotency makes them harmless at the business layer.
Whenever you say “this is idempotent”, ask four boundary questions.
Idempotent with respect to what state.
Over what time window.
Under what concurrency model.
Against which side effects.
If the boundary is vague, the guarantee is a lie. Name it in code, docs, and tests. Put it in your acceptance criteria.
Why concurrency changes the problem
Concurrency means two or more requests are in flight at the same time. When that happens, you can have a race condition. That is when both requests read the same state before any of them writes the dedupe record.
A lock is a rule that lets only one request hold the right to update a row at a time. A unique constraint is a rule that rejects duplicates even if two requests arrive together.
That is why idempotency is not just a key. It is also a guard. You need a unique constraint, a lock, or a transactional check so only one request wins.
Here is the race in one picture.
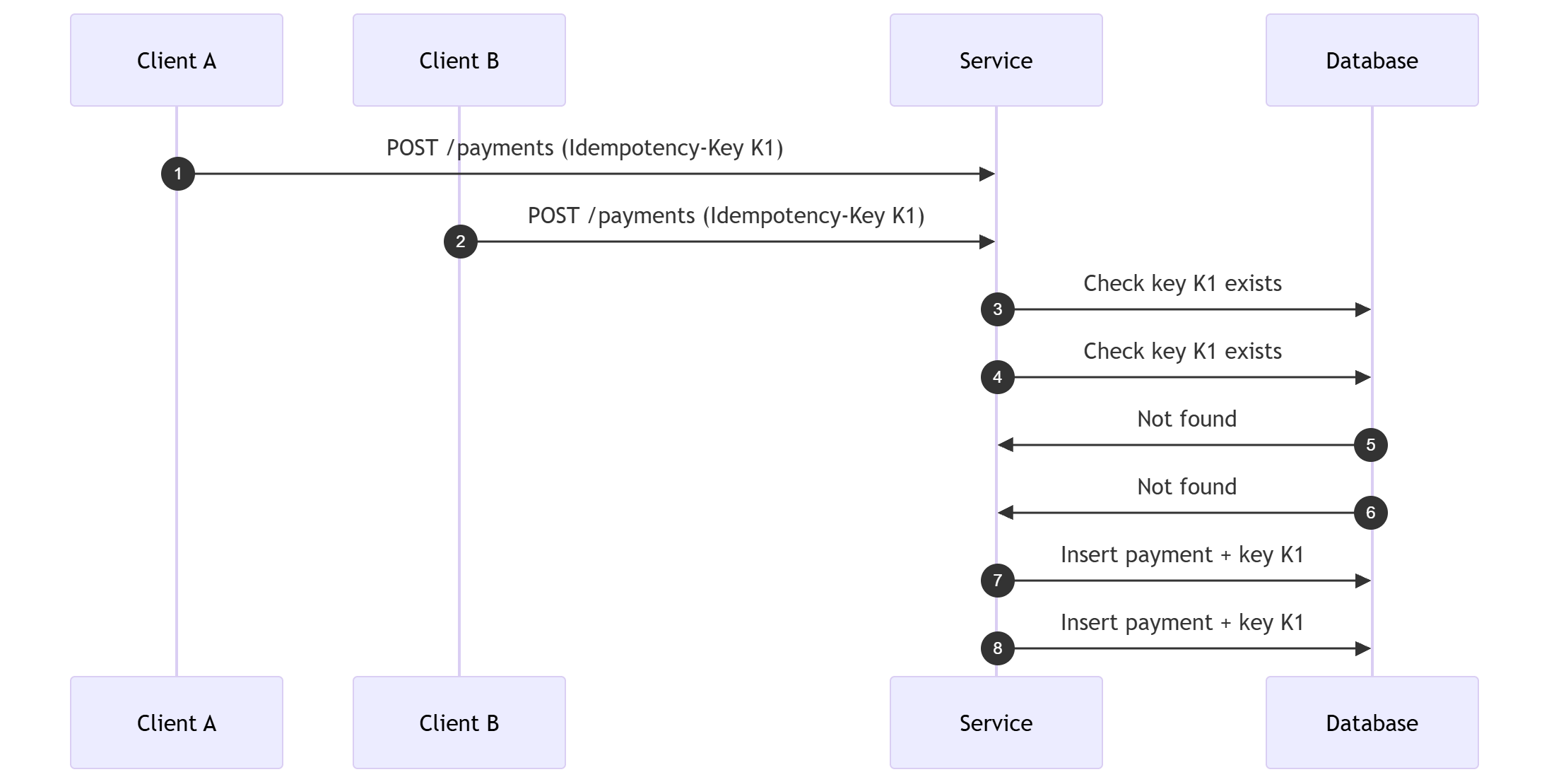
Without a unique constraint, both inserts can succeed. With a unique constraint, the second insert fails and you return the stored result.
Vocabulary that makes the rest possible
You cannot reason about idempotency without a shared vocabulary.
Delivery guarantees:
At most once: it might be lost, but it is not duplicated.
At least once: it is not lost, but it can be duplicated.
Exactly once: no loss and no duplicates within a defined boundary.
Exactly once delivery vs processing vs effects:
Exactly once delivery is a broker claim.
Exactly once processing is a consumer claim.
Exactly once effects is a system claim across side effects. Exactly once delivery rarely covers side effects outside the broker.
Most systems aim for effectively once. Duplicates can happen internally, but the external state behaves as if each logical operation happened once. For example, you might see the same message twice, but only one row is inserted and the user sees a single order. Effectively once is what the customer experiences, not what the transport promises.
Deterministic processing:
If you replay the same input, you must get the same output.
If logic depends on time, randomness, or unstable ordering, idempotency becomes fragile. Immutable inputs make determinism easier to enforce.
Idempotency key:
A unique identifier for the client intent, reused across retries so the server can detect duplicates and return the same result. Treat it as an intent id, not a user id.
Fencing token:
A monotonically increasing token that blocks stale actors from writing. It is a safety latch for concurrency, not a retry key.
Agree on these terms, then codify them in your APIs and data models.
Deep dive
HTTP APIs
HTTP gives you hints, not guarantees. Your business semantics decide whether retries are safe.
Method expectations are useful, but incomplete.
GET and HEAD are safe and therefore idempotent.
PUT is idempotent if it replaces a resource with the given representation.
DELETE is idempotent if deleting twice leaves the resource deleted.
POST is not inherently idempotent because it often creates a new subordinate resource.
Do not hide behind protocol semantics. Model the business effect, then choose the method. If you must use POST for a side effect, you must define an idempotency key policy.
Fix option A: client generated IDs with PUT
Let the client choose the id and use PUT. If the same id is retried, the state converges. PUT only works if the client can safely own the identifier.
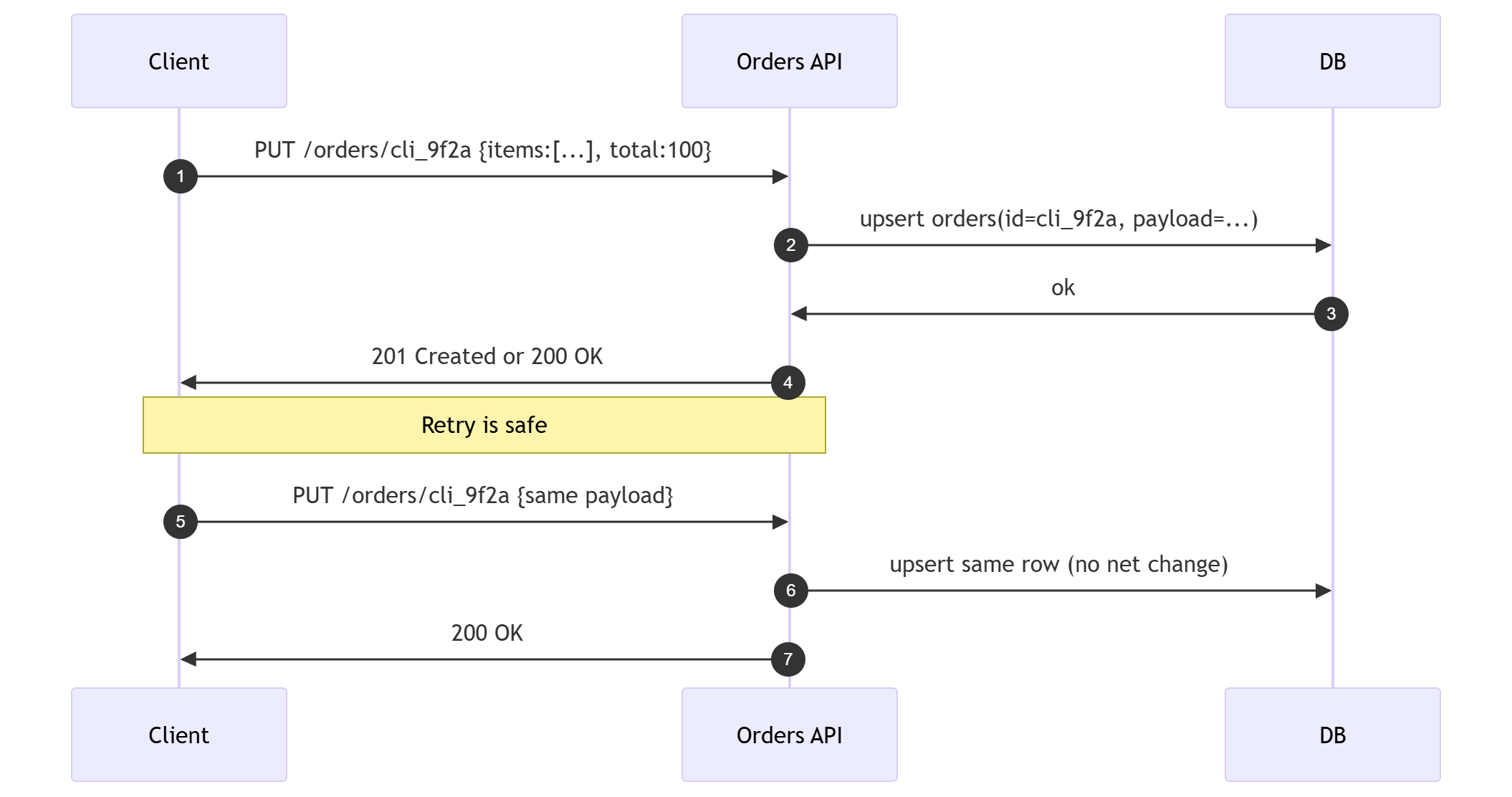
This is simple, but not always feasible when you need server assigned ids or the operation is not a resource replacement.
Fix option B: idempotency keys for POST
For operations that are not replaceable, use an idempotency key. A stable key makes retries safe.
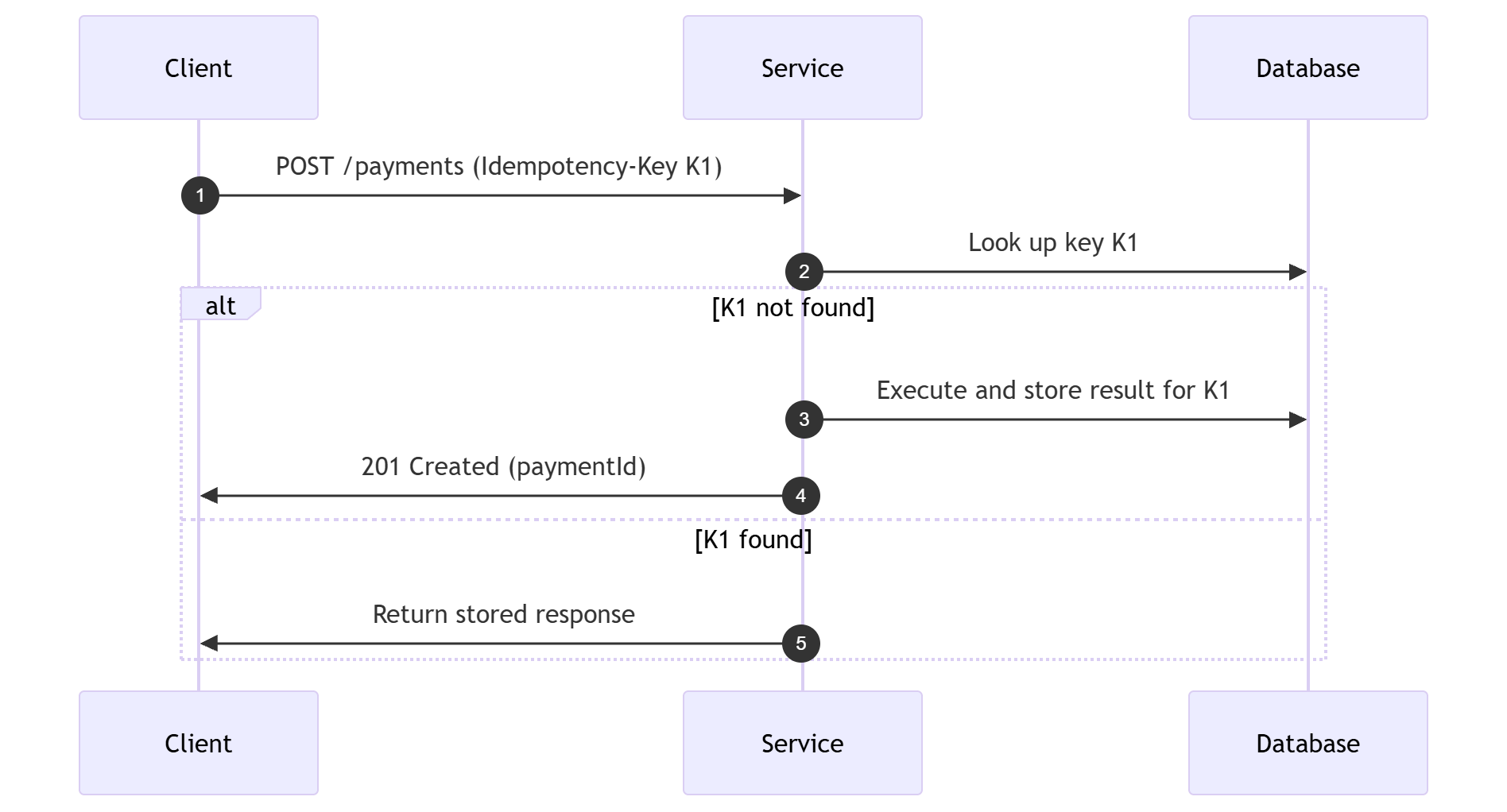
The IETF draft for Idempotency-Key and production guidance from AWS and Stripe converge on the same idea. Retries must return the same outcome for the same intent.
Implementation details that matter
Storage location. Keep idempotency records in a durable store, ideally the same one that holds the business state.
What to store. Key, request hash, status, and the canonical response. The hash protects you from reusing the same key for different payloads. If the same key arrives with a different payload, return a clear error.
Concurrency. Two identical requests can arrive at the same time. Use a unique constraint or lock so only one executes. Store an in progress state if the first request is still running.
Retention. Keys cannot live forever. Decide the window and make it explicit. It should be longer than your client retry window.
Partial failures. If the first attempt partially applied, you must either roll back or record enough state to finish cleanly.
If you cannot answer these, you are not done.
Conditional requests: idempotency plus concurrency control
Idempotency protects retries. It does not protect against lost updates between writers. Use conditional requests for that.
Server returns an ETag, which is a version label for the current resource state.
Client updates using If-Match.
If the version changed, the server rejects the update. If-Match protects against lost updates, not duplicate requests.
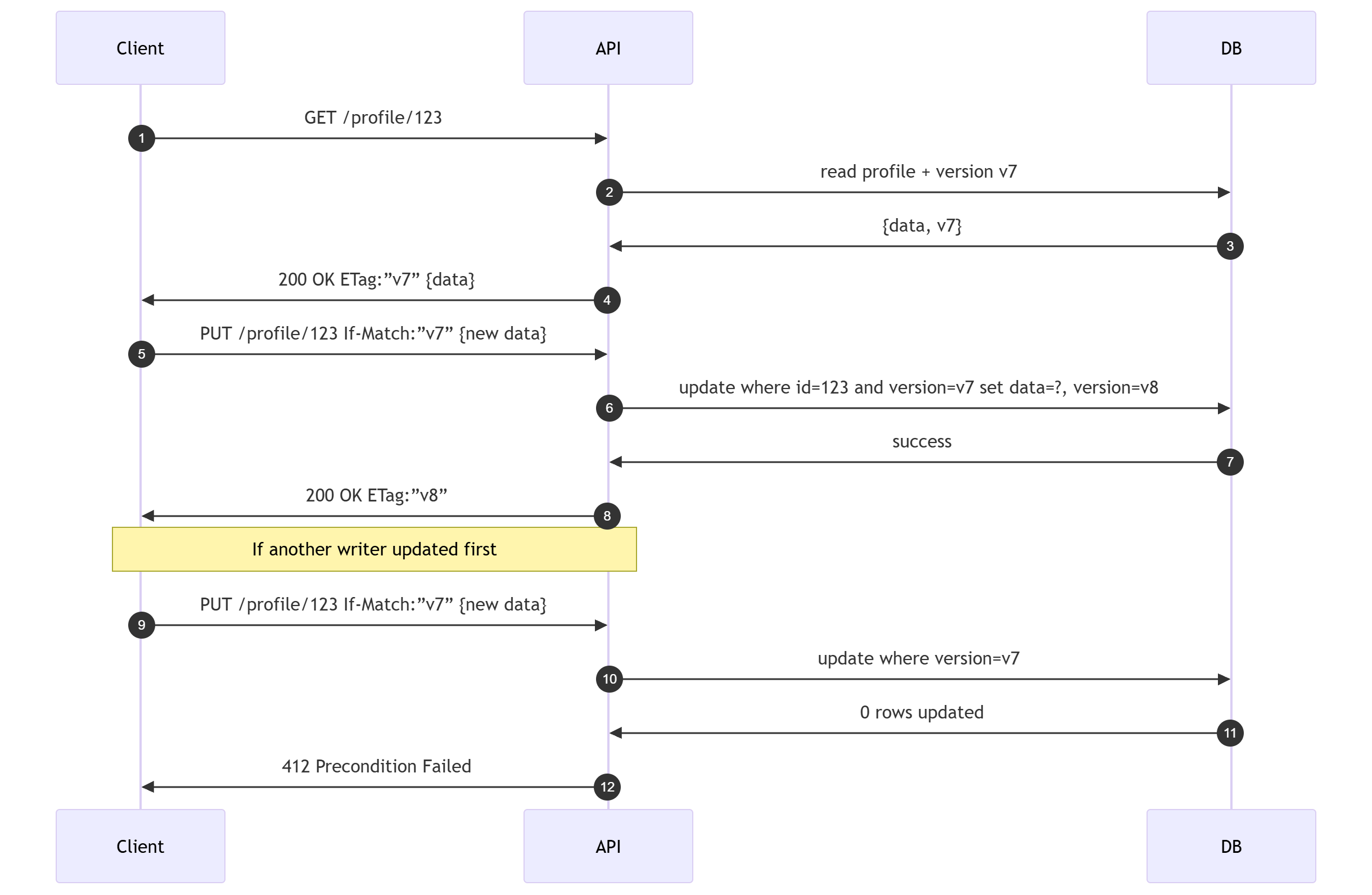
Decide which endpoints need both idempotency and concurrency control, then enforce it.
Databases and state transitions
Most idempotency techniques are just database techniques with discipline. The goal is always the same. Make state converge to a target, not accumulate effects.
Naturally idempotent operations:
SET status = PAID is idempotent.
INSERT row is not idempotent unless a unique constraint gates it.
counter = counter + 1 is not idempotent.
Prefer set to a value over increment when you need safe retries.
Unique constraints as a dedupe gate
If a logical operation has a natural unique identifier, enforce it in the database. A unique constraint is a rule that rejects duplicate values. That turns retries into harmless conflicts.
Example: each payment has a payment_intent_id.
Insert with a unique constraint on payment_intent_id.
On retry, the insert fails and you return the existing row instead of creating a new one.
Let the database do the dedupe. It is faster and more reliable than application guesses.
Upsert by business key
If you can define a stable business key, use upsert or merge. Upsert means insert or update using that key. The operation converges to one row. It still relies on a unique index to be safe under concurrency.
Record the last applied input
When applying events or messages, store metadata that tells you if a given input was already applied.
Each input has a sequence or offset.
The row stores last_applied_sequence.
Update only when the input sequence is greater.
That is the database version of an inbox. It is optimistic concurrency using a sequence guard.
Fencing to block stale actors
If multiple workers can act on the same entity, use a fencing token so only the latest worker can write.
Acquire a lease with token t, then require token t on writes. Any previous token cannot write anymore.
A simple way to think about it is a monotonic counter. Only the latest counter value can make changes.
“The production of an additional record is inconsequential since updating entity data is idempotent.”
Adam Bellemare, Building Event-Driven Microservices
Treat idempotent updates as a first class design choice, not a side effect.
Event-driven systems and messaging
Event driven systems default to at least once delivery because it survives failure. Duplicates are not a bug, they are a design input.
Why duplicates happen
Producer retries after a timeout.
Consumer crashes after processing but before acknowledging.
A relay republishes after a crash.
You can try to prevent duplicates at the producer, but you must tolerate them at the consumer.
Consumer side idempotency: the Inbox pattern
The inbox pattern records which message ids have been processed. Think of it as a table of processed message ids. It turns duplicate deliveries into no ops. Retention must cover the maximum redelivery window, or you risk reprocessing old duplicates. The inbox insert and the business side effects should be in the same transaction.
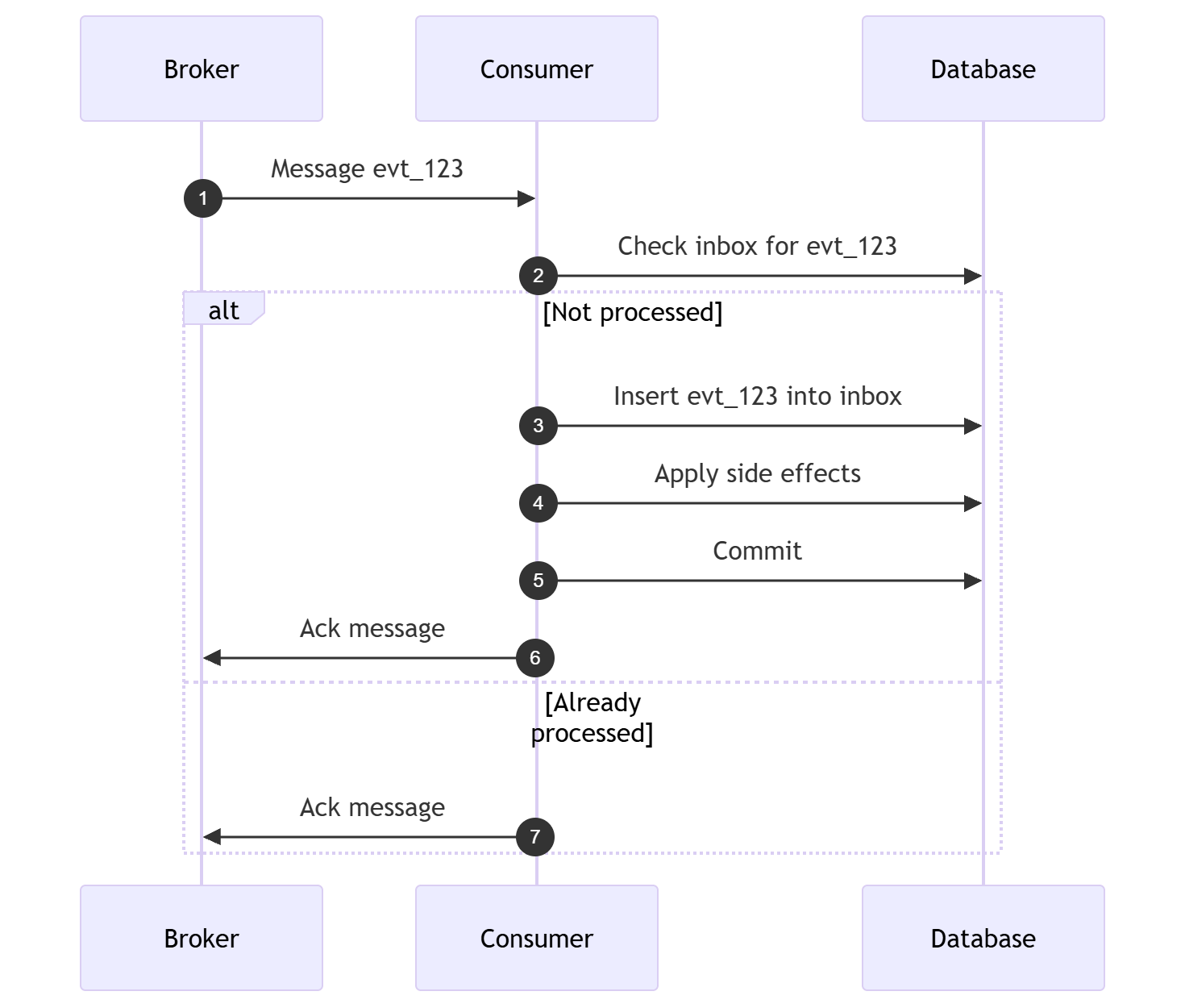
“If the application logic that processes messages is idempotent, then duplicate messages are harmless.”
- Chris Richardson, Microservices Patterns
Design the inbox as a boundary. It should be as durable as the state it protects.
Producer side reliability: the Outbox pattern
The outbox pattern makes the database update and the intent to publish part of the same transaction, then publishes asynchronously. Dual write means you update the database and publish a message in two separate steps without atomicity. The outbox removes that failure mode. Outbox rows are immutable. Only the publish marker changes.
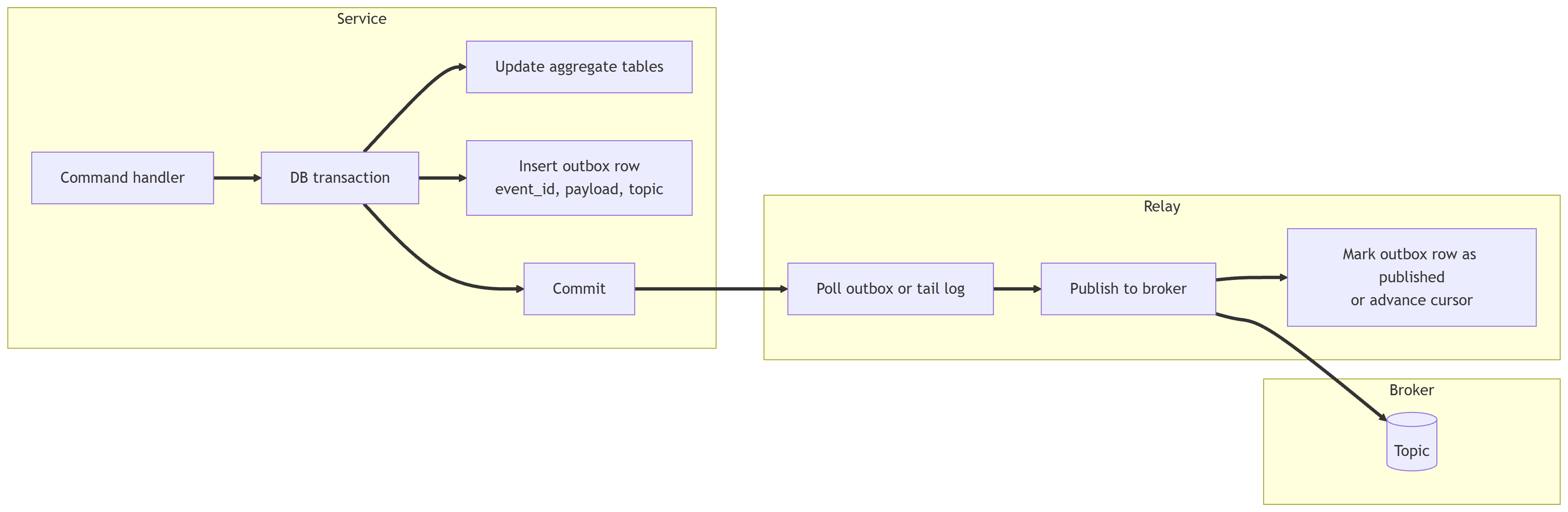
Even with an outbox, the relay can publish twice if it crashes after publish and before marking. That is why consumer idempotency is still required.
Event-driven workflows: choreography and idempotent steps
In event driven sagas, each step must be idempotent. A saga is a multi step workflow across services. Retries can happen at any hop.
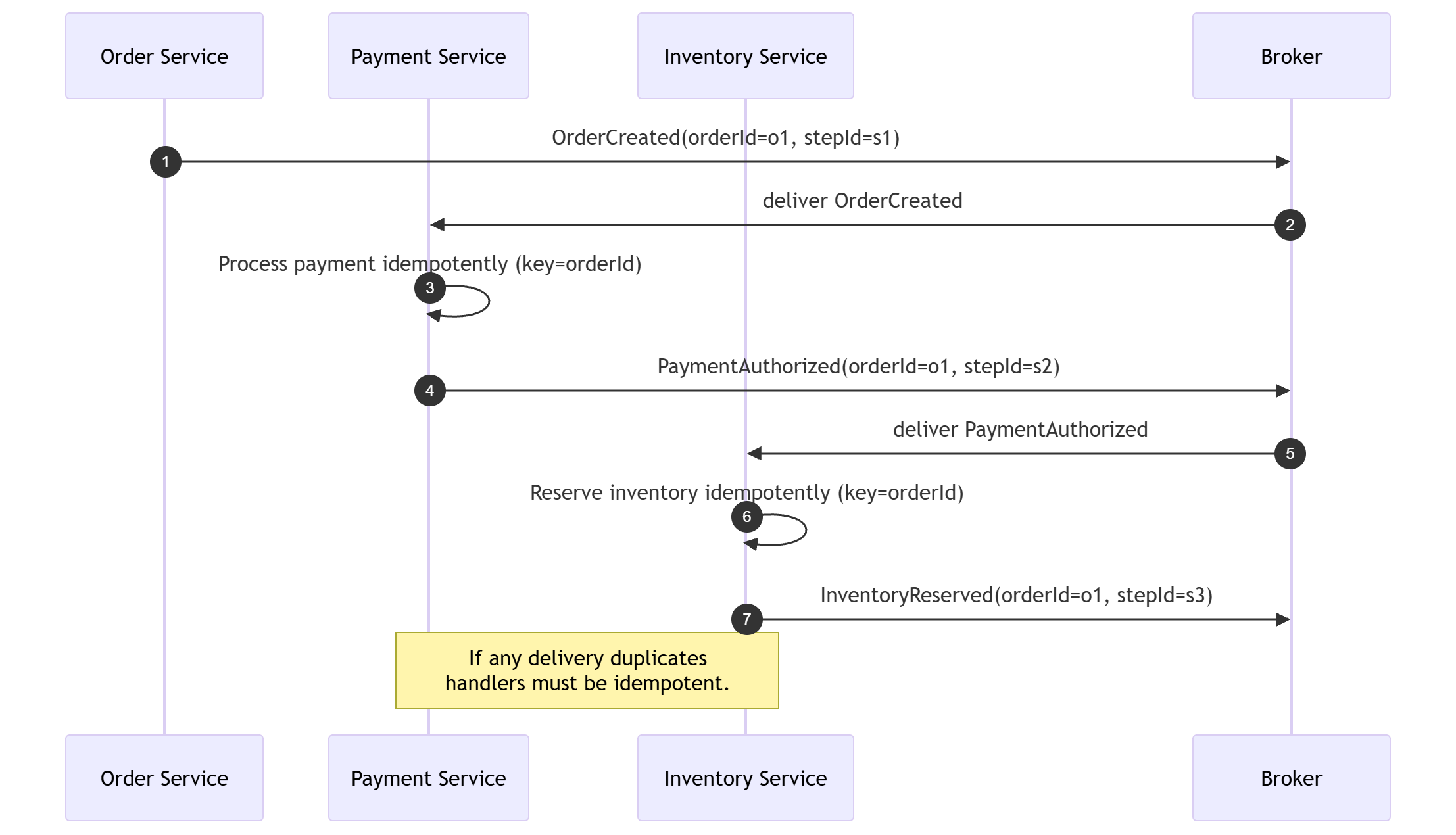
Treat idempotency as the contract of every step, not a retrofitted patch. A stable key like orderId or commandId is the usual anchor.
Stream processing and exactly once
Stream processing is where the phrase exactly once becomes slippery. Delivery, processing, and effects are three different promises.
Strategy A: transactional commit of input, state, and output
If the platform supports it, atomically commit three things: input position, state update, and output. An offset is the position in the log. A state store is the place where the current computed result lives. The commit boundary is the single point where input, state, and output move forward together.
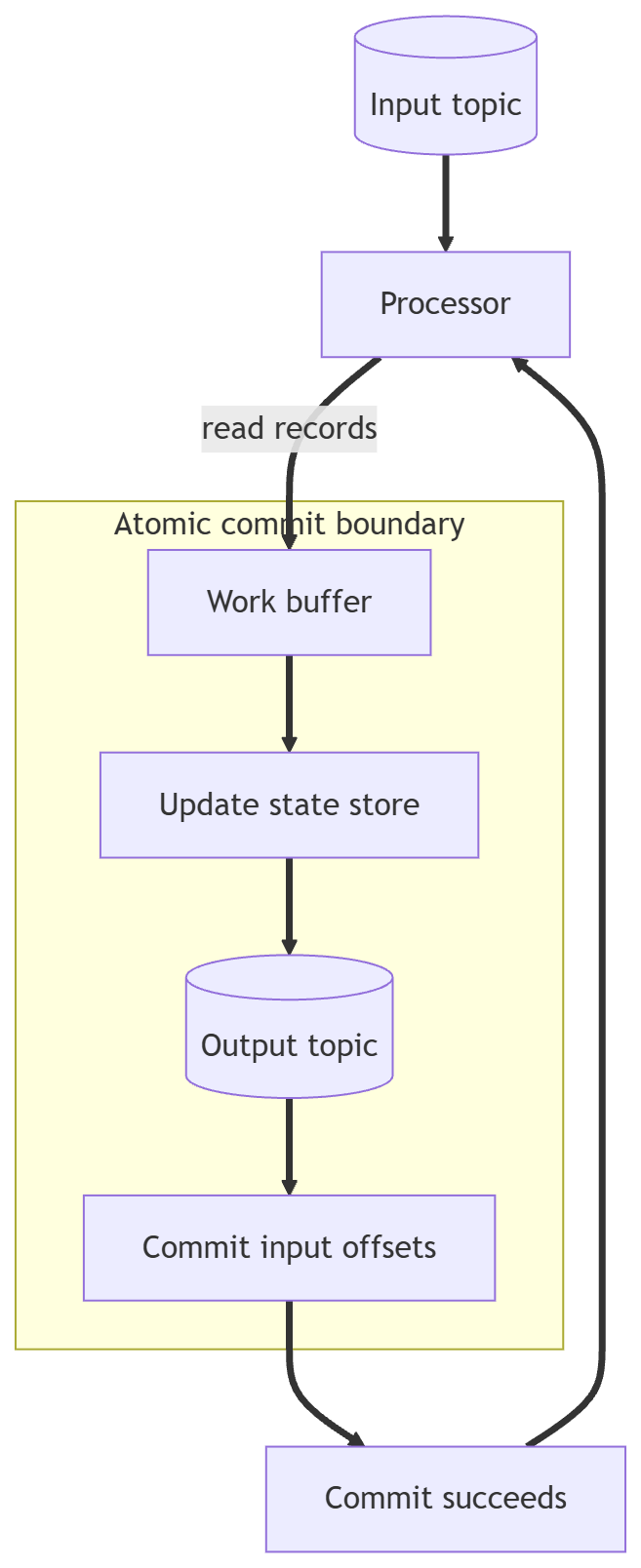
If the commit fails, nothing is visible and you can retry without drift. That is the cleanest path when the platform supports it.
Strategy B: idempotent operations plus replay
If you cannot atomically bind offsets and writes, you can still get effectively once outcomes by combining:
deterministic processing
idempotent sinks
last applied sequence checks
This works if you can replay inputs in a stable order and your sinks converge by key. If your sink cannot dedupe, your replay will drift.
Do not promise exactly once unless you can draw the commit boundary.
ETL, batch pipelines, and backfills
ETL (Extract, Transform, Load) is a retry machine. Schedules rerun, tasks fail halfway, and backfills replay months of history. Backfill means rerunning historical data to fix or rebuild results.
Failure mode
Extract and transform succeed, load partially succeeds, and a retry appends again. You now have duplicate rows and false metrics.
Pattern A: overwrite by partition
If data is partitioned by date, compute the partition deterministically and overwrite it each run. This is batch idempotency. It is the batch equivalent of PUT for a date slice.
Pattern B: stage then swap
Write to a staging dataset, validate counts, then atomically publish by swapping names or pointers. It is publish by pointer, not by partial append.
Pattern C: merge by business key
If you have a unique key, use merge to update existing rows and insert missing ones.
Pattern D: checkpoint or watermark
Persist the last processed id or timestamp, then only process new inputs. If you overlap windows, make the load idempotent so replays do not hurt you. Watermark is the last processed time you trust.
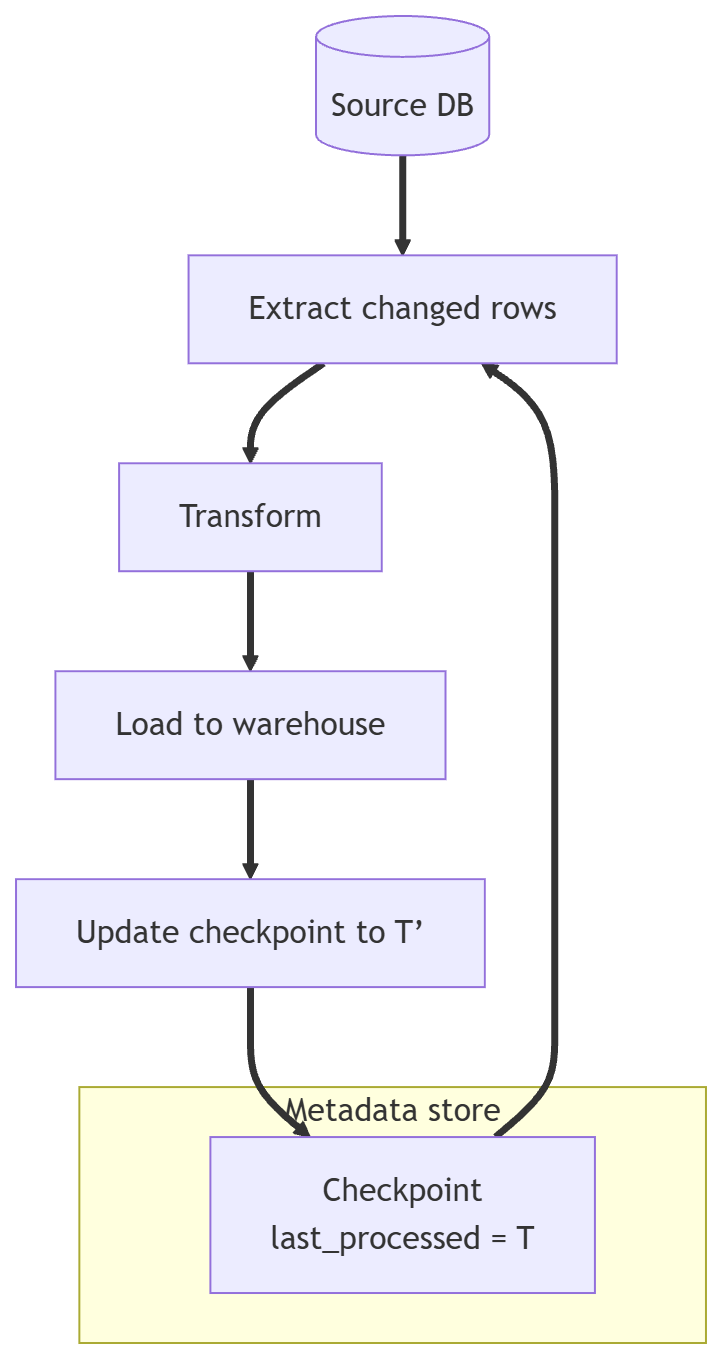
If you cannot safely replay a batch, you do not have a pipeline. You have a gamble.
Serverless, background jobs, and task queues
Serverless platforms and task queues retry by design. Visibility timeouts and elastic concurrency make duplicates normal. A visibility timeout is the period where a message is hidden before the queue redelivers it.
For a job like send invoice email, use a dedupe key such as invoiceId.
store email_sent_at in a table
send only if it is null
write the timestamp in the same transaction as the business change when possible
For charge payment, use the payment intent id as the idempotency key and make the provider call idempotent as well. If the provider supports idempotency keys, use them. Do not rely on your own retries alone.
Resilience is the ability to recover safely. Idempotency is the tool that makes recovery repeatable. Retries with backoff, failover, replays, and backfills all rely on being able to retry without changing the outcome.
Resilience needs retries. Retries need idempotency. Design it so the second run is boring.
Idempotency mastery checklist
Use this as a full ladder. Each line is a concrete action or decision. If you cannot do one, you are not done.
Definitions and boundaries
Define the operation in one sentence before defining its idempotency.
Name the state that must converge, not just the response.
List every side effect, even the small ones.
Decide the time window in which duplicates can appear.
Decide what counts as the same intent.
Write the boundary in your acceptance criteria.
Define the dedupe key format and its scope.
Declare whether the operation is safe, idempotent, or neither.
Document what happens on a retry when the first attempt succeeded.
Document what happens on a retry when the first attempt partially failed.
Retries and client behavior
Specify which errors are retryable.
Set a retry budget so clients do not retry forever.
Use exponential backoff, which means waiting longer after each failure, to avoid retry storms.
Add jitter, a small random delay, so many clients do not retry in sync.
Ensure a retry uses the same idempotency key.
Prevent clients from accidentally generating a new key on retry.
Decide whether the server returns the stored response or a 409 style conflict.
Log the idempotency key on every retry path.
Ensure monitoring tracks retry volume, not just errors.
Confirm the retry window is shorter than the key retention window.
HTTP design
Prefer PUT with client owned IDs when possible.
Use POST only when you cannot model the operation as a resource replacement.
Require Idempotency-Key on POST that creates side effects.
Store a hash of the request payload with the key.
Reject the same key with a different payload.
Use ETag and If-Match for concurrent updates.
Return the same response body for the same idempotency key.
Make the response idempotent, not just the action.
Document which endpoints are idempotent in your API docs.
Write one integration test that retries the same request.
Concurrency and data integrity
Assume two requests can arrive at the same time.
Use a unique constraint to enforce single intent execution.
Use a lock when a unique constraint is not enough.
Store an in progress state to block a second worker.
Treat any check before insert as a race window.
Keep dedupe logic inside the same transaction as the side effect.
Ensure only one transaction can claim the key.
Test concurrent retries with two clients at once.
Use fencing tokens when multiple workers can write.
Do not rely on in memory caches for dedupe.
Database patterns
Use unique constraints as the first line of defense.
Prefer upsert by business key over insert by surrogate key.
Use set to value updates when you need idempotency.
Avoid counter increments unless you can dedupe first.
Store last_applied_sequence for event driven updates.
Guard updates with a greater than sequence check.
Keep idempotency records in the same database as the state.
Define how long dedupe records are retained.
Use transactions to bind dedupe and state changes.
Use explicit error handling for unique constraint violations.
Messaging consumption
Assume at least once delivery, even when the broker claims otherwise.
Use an inbox table for every consumer that writes state.
Insert the message id before applying side effects.
Make inbox insert and business write part of one transaction.
Use a unique constraint on message id.
Decide how long you keep inbox records.
Log dedupe hits as normal, not as errors.
Treat redelivery as expected, not as a bug.
Document the dedupe key for each event type.
Test replays with duplicate messages.
Outbox and publishing
Write the outbox record in the same transaction as the state change.
Treat the outbox row as immutable.
Mark publish status in a separate field.
Expect the relay to publish twice and design for it.
Use a retry policy for the relay with backoff.
Store publish errors for diagnosis.
Monitor outbox lag as a first class metric.
Use CDC, change data capture, only after the polling relay is stable.
Keep event payloads versioned and explicit.
Avoid publishing events without a stable message id.
Stream processing
Define your commit boundary first.
Prefer transactional state and output when available.
Make sinks idempotent when transactions are not available.
Store last_applied_sequence in the sink.
Keep processing deterministic across restarts.
Avoid time based randomness in core logic.
Use stable ordering keys for partitioned streams, which are per key ordered slices.
Expect replay after failure and design for it.
Verify that dedupe works with large replays.
Document exactly once claims and their limits.
ETL and batch
Make each batch run safe to replay.
Prefer overwrite by partition for time based data.
Use stage then swap for large publishes.
Use merge by business key when you need partial updates.
Track watermarks and define late data handling.
Use overlapping windows only with idempotent loads.
Prevent two runs from publishing the same partition.
Keep checkpoints in a durable store.
Test a backfill on a small slice before full scale.
Record the batch id in the output for traceability.
Operations and testing
Add a test that retries the same request twice.
Add a test that retries concurrently from two clients.
Add a test that replays messages in a consumer.
Log idempotency keys and dedupe decisions.
Track duplicate rate as a metric.
Track outbox lag and inbox growth.
Alert on idempotency key conflicts with different payloads.
Include idempotency behavior in incident runbooks.
Review idempotency boundaries during design reviews.
Reevaluate retention windows when retry policies change.
Conclusions
Idempotency is the simplest concept with the biggest impact on reliability. It turns retries from dangerous to routine.
Idempotency is never a property of code in isolation. It is a property of an operation relative to a boundary: state, time window, concurrency, and side effects.
Exactly once is a story about composition. You rarely get it end to end. What you can build is effectively once outcomes by combining idempotent APIs, idempotent consumers, dedupe stores, and reliable publishing.
In practice this ties directly to event-driven architecture choices and transactional outbox design. If those two are weak, idempotency promises collapse under retry pressure.
If it fits your context, systemic impact is fewer hidden inconsistencies and cleaner recovery paths. If it fits your context, team health improves because on call incidents become repeatable, not dramatic.
Choose where idempotency is mandatory, document the boundary, and enforce it with tests. Write at least one test that retries the same request and asserts a single side effect. Start by listing the operations where duplicates would be catastrophic, then fix those first.
References
Richardson, Chris. Microservices Patterns.
Bellemare, Adam. Building Event-Driven Microservices.
Kleppmann, Martin. Designing Data-Intensive Applications.
Editor, RFC. RFC 9110: HTTP Semantics. https://www.rfc-editor.org/rfc/rfc9110
IETF, Working Group. The Idempotency-Key HTTP Header Field (draft). https://datatracker.ietf.org/doc/draft-ietf-httpapi-idempotency-key-header/
Amazon Web Services, Builders Library. Making retries safe with idempotent APIs. https://aws.amazon.com/builders-library/making-retries-safe-with-idempotent-APIs/
Leach, Brandur. Designing Robust and Predictable APIs with Idempotency. https://stripe.com/blog/idempotency
MDN Web Docs, Documentation. HTTP Conditional Requests. https://developer.mozilla.org/en-US/docs/Web/HTTP/Conditional_requests
Richardson, Chris. Pattern: Transactional Outbox. https://microservices.io/patterns/data/transactional-outbox.html
Confluent, Team. Exactly-once Semantics Are Possible: Here’s How Apache Kafka Does It. https://www.confluent.io/blog/exactly-once-semantics-are-possible-heres-how-apache-kafka-does-it/
Google Cloud, Documentation. Exactly-once delivery. https://cloud.google.com/pubsub/docs/exactly-once-delivery
Google Cloud, Documentation. Exactly-once in Dataflow. https://cloud.google.com/dataflow/docs/concepts/exactly-once