
Faster code, slower system
AI did not break software delivery. It exposed the constraint we were already ignoring.


A restaurant buys a machine that can chop vegetables three times faster than any cook. At first, everyone celebrates. Prep is flying. Bowls fill up. Ingredients appear before anyone has time to ask for them. The manager walks past the counter and sees motion everywhere. The machine looks like productivity made visible.
Then dinner service starts.
The pass fills with unfinished plates. The head chef keeps stopping to check whether the ingredients match the orders. Waiters wait longer. Customers complain. More food leaves the kitchen, but more comes back. The machine did exactly what it promised. It accelerated one station. The kitchen did not become faster. It became louder, busier, and more fragile.
The machine was faster. Dinner was not.
That is the mistake many software organizations are making with Artificial Intelligence (AI). They are treating code generation as if it were the kitchen. It is not. It is one station inside a larger system.
The Faros AI Engineering Report 2026 gives us one of the clearest telemetry-based pictures of this problem so far. Across approximately two years of data from 22,000 developers and 4,000 teams, Faros reports real acceleration: task completion is up, epics completed per developer are up, and code-related tasks have increased sharply. But the same report also shows the bill arriving downstream: bugs, incidents, review time, code churn, cognitive load, and rework are rising too. Faros calls this the “Acceleration Whiplash”. The phrase is good, but the underlying mechanism is older than AI. It is suboptimization.
The argument is not that AI is useless. That would be too easy, and it would be wrong. The argument is more uncomfortable.
AI is powerful precisely because it can optimize the wrong part of the system at industrial speed.
TL;DR

AI can accelerate local coding output, but local speed is not system productivity.
A controlled GitHub Copilot experiment found that developers with access to Copilot completed a JavaScript HTTP server task 55.8% faster than the control group. Faros also reports acceleration under high AI adoption: task throughput per developer is up 33.7%, epics completed per developer are up 66.2%, and tasks completed per team with an associated PR are up 210%. That matters, but it only tells us that one station in the system became faster. It does not prove that the whole delivery system became healthier, safer, or more valuable.Software delivery is not code generation.
Code generation is one part of a wider system that includes product judgment, specification, design, review, testing, security, deployment, operation, feedback, and future change. A pull request is output. A deployed change is closer to throughput. Real outcome appears only when users receive valuable, safe, maintainable change.The Faros data suggests that AI increased upstream output while downstream pressure grew.
The report shows larger PRs, more files touched, longer review times, more waiting, more bugs, more incidents, more reopened work, and more code churn. That pattern is important because it does not describe simple productivity. It describes acceleration followed by absorption problems.This is not a contradiction. It is suboptimization.
A subsystem can improve while the whole system gets worse. If code generation is not the constraint, making it faster may simply push more work into review, QA, deployment, production, or incident response. The pressure does not disappear. It accumulates around the real bottleneck.Strong foundations are not immunity.
Faros’ tenth-takeaways article says that even organizations with mature DevOps practices, high DORA metrics, and disciplined delivery processes experienced the same downstream deterioration as others. That does not mean engineering foundations do not matter. It means maturity is capacity, not infinite absorption.In Theory of Constraints (TOC) terms, much AI-generated code may be inventory, not throughput.
If generated code waits for review, waits for QA, waits for deployment, comes back as rework, or creates incidents, it has not yet become value. It is work inside the system, consuming capacity and attention. More inventory is not the same as more throughput.The scarce resource is no longer code. It is judgment.
When code becomes cheap to generate, the expensive part becomes deciding whether the change is correct, valuable, safe, reversible, coherent with the architecture, and worth carrying into the future. Review is not a cleaning service for generated code. It is a scarce decision point.Software starts as an economic liability, not an asset.
Software becomes an economic asset only when the value it creates exceeds the cost, risk, and attention it permanently consumes. AI may reduce the cost of creating software liabilities faster than the organization improves its ability to turn them into assets.Context helps, but it does not make LLM output safe by itself.
Better context can reduce preventable mistakes, but it does not remove LLM error, context-window limits, retrieval failures, agent variance, or the need for human judgment. The goal is not blind trust. The goal is lower preventable rework.Context management has a cost too.
Teams often have to maintain prompts, rules, memory files, context documents, agent instructions, workflows, examples, tests, and guardrails because the tools do not reliably manage all of this by themselves. That effort is not free. It is operating expense.The leadership question changes.
The question is not “How do we get more AI-generated code?” The question is: “Where is our system constrained, and is AI protecting, elevating, or flooding that constraint?”The conclusion is simple.
Do not let AI set the rhythm of the system. The constraint sets the rhythm. AI is not the drum. The constraint is.
Index
The promise was local speed
Code generation is not software delivery
The Faros data shows the bill arriving downstream
This is not a contradiction. It is suboptimization
Code generation was not the constraint
AI fed the bottleneck
The system pushed back
The scarce resource is judgment
Cheap code is not a cheap asset
What leaders should measure now
How to use AI without flooding the system
Conclusions: AI is not the drum
References
The promise was local speed
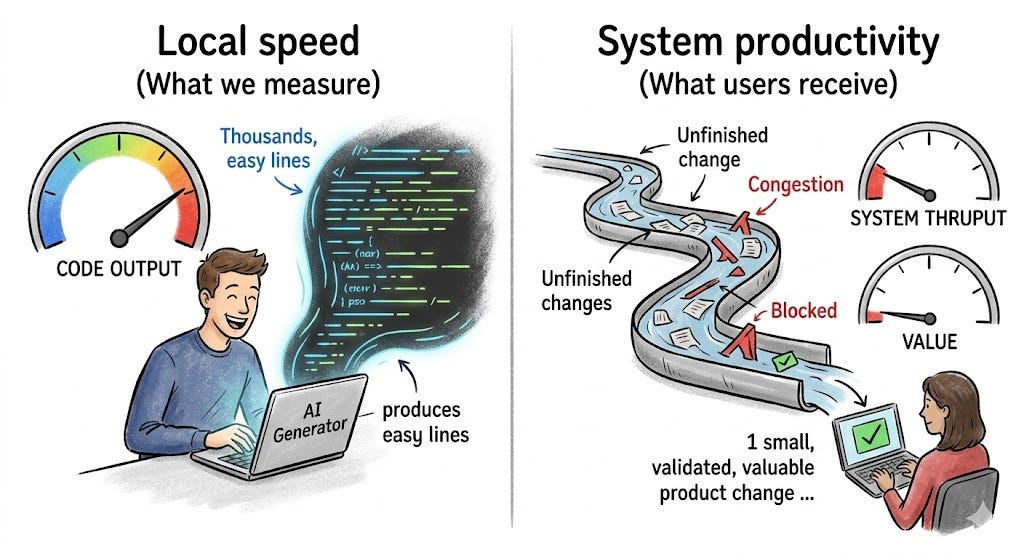
There is a version of the AI productivity story that is true. We should begin there.
In a controlled experiment on GitHub Copilot, developers with access to Copilot completed a JavaScript HTTP server task 55.8% faster than the control group. That is not a minor improvement. In a bounded context, with a clear task and a narrow feedback surface, AI can reduce the time between intention and code.
Faros sees the same kind of acceleration at the level of engineering activity. In its 2026 report, task throughput per developer is up 33.7%, epics completed per developer are up 66.2%, PR merge rate per developer is up 16.2%, and tasks completed per team with an associated PR are up 210%. AI is clearly increasing local output. It is making the chopping station faster.
But the word “local” matters.
Local speed is not system speed.
A local gain is not a system gain. A developer can finish a task faster while the team delivers value more slowly. A team can merge more pull requests while production becomes less stable. An organization can increase AI adoption while increasing the cost of review, testing, incident response, coordination, and future change.
This is where the productivity debate often becomes confused. One side looks at the developer and sees speed. The other side looks at production and sees pain. Both can be looking at real evidence. They are just looking at different parts of the system.
METR’s 2025 randomized controlled trial makes that gap hard to ignore. In that study, 16 experienced open-source developers worked on 246 real tasks in repositories they already knew well. Before starting, developers expected AI to reduce completion time by 24%. Afterward, they still believed AI had reduced completion time by 20%. The measured result went the other way: with AI allowed, developers took 19% longer.
That result does not prove that AI always slows developers down. It does prove something more useful for leaders: perceived acceleration and measured system performance can diverge. The work can feel easier while the system becomes slower to deliver. That is not a paradox. That is a systems problem.
Productivity in software is not the amount of code produced per unit of time. It is the system’s ability to turn scarce attention, knowledge, and investment into valuable, safe, maintainable change.
Code generation is not software delivery
A restaurant is not a chopping machine. It is a coordinated system of ordering, preparation, cooking, plating, quality control, service, feedback, cleaning, and learning. A software organization is similar. Coding matters, but it is only one station inside a wider flow.
Software delivery includes product judgment, specification, design, coding, review, testing, security, deployment, observability, incident response, customer feedback, and future change. If one station accelerates faster than the others can absorb, the result is not necessarily throughput. It may be congestion.

Output is what the team produces. Throughput is what successfully flows through the system. Outcome is what matters after users touch it.
A pull request is output. A merged pull request is still not necessarily outcome. A deployed change is closer, but even deployment is not enough if the change increases incidents, damages trust, or creates future drag. The system goal is not “more code”. The goal is valuable, safe, validated change.
That distinction sounds obvious until AI enters the room. AI makes the most visible station faster, so the organization starts treating that station as if it were the whole system. Dashboards celebrate accepted suggestions, generated lines, closed tickets, and merged PRs. The kitchen applauds the chopping machine while the pass fills with plates no one can safely send out.
AI lowers the cost of starting. But in a constrained system, the cost that matters is often the cost of finishing.
The Faros data shows the bill arriving downstream
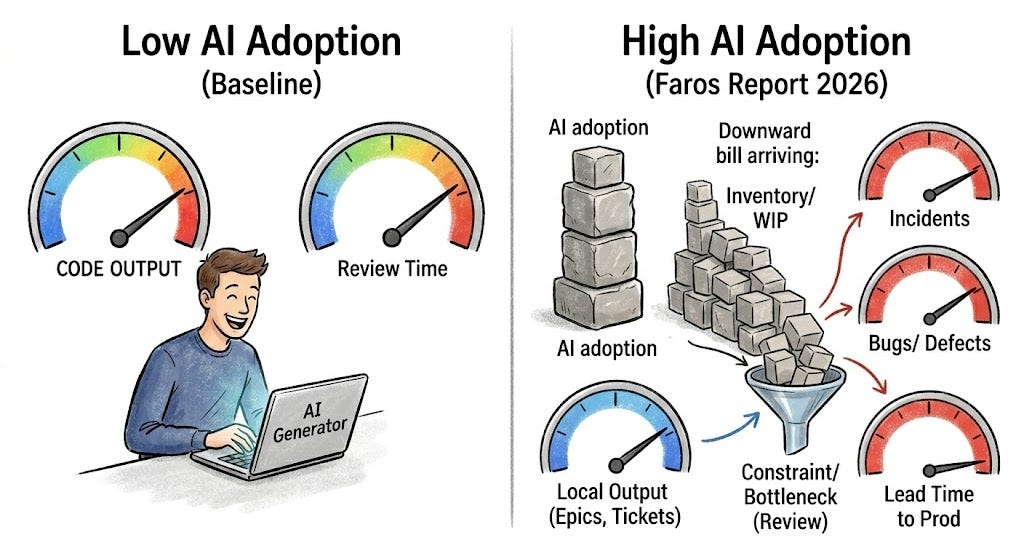
The Faros report is not just another opinion survey. It analyzes telemetry from task management systems, IDEs, static analysis tools, CI/CD pipelines, version control systems, incident management systems, and HR metadata. Faros standardized metrics per company, used Spearman rank correlation, reported statistically significant relationships with p-value below 0.05, required data from at least six companies, and compared each team’s two lowest AI-adoption quarters with its two highest AI-adoption quarters. The report also states an important limitation: the 2026 and 2025 datasets are independent cross-sections, so comparisons with the previous report are directional, not precise year-over-year longitudinal claims.
That matters because the pattern in the data is not simply “AI bad” or “AI good”. The pattern is more interesting: upstream output rises, then downstream absorption gets worse.
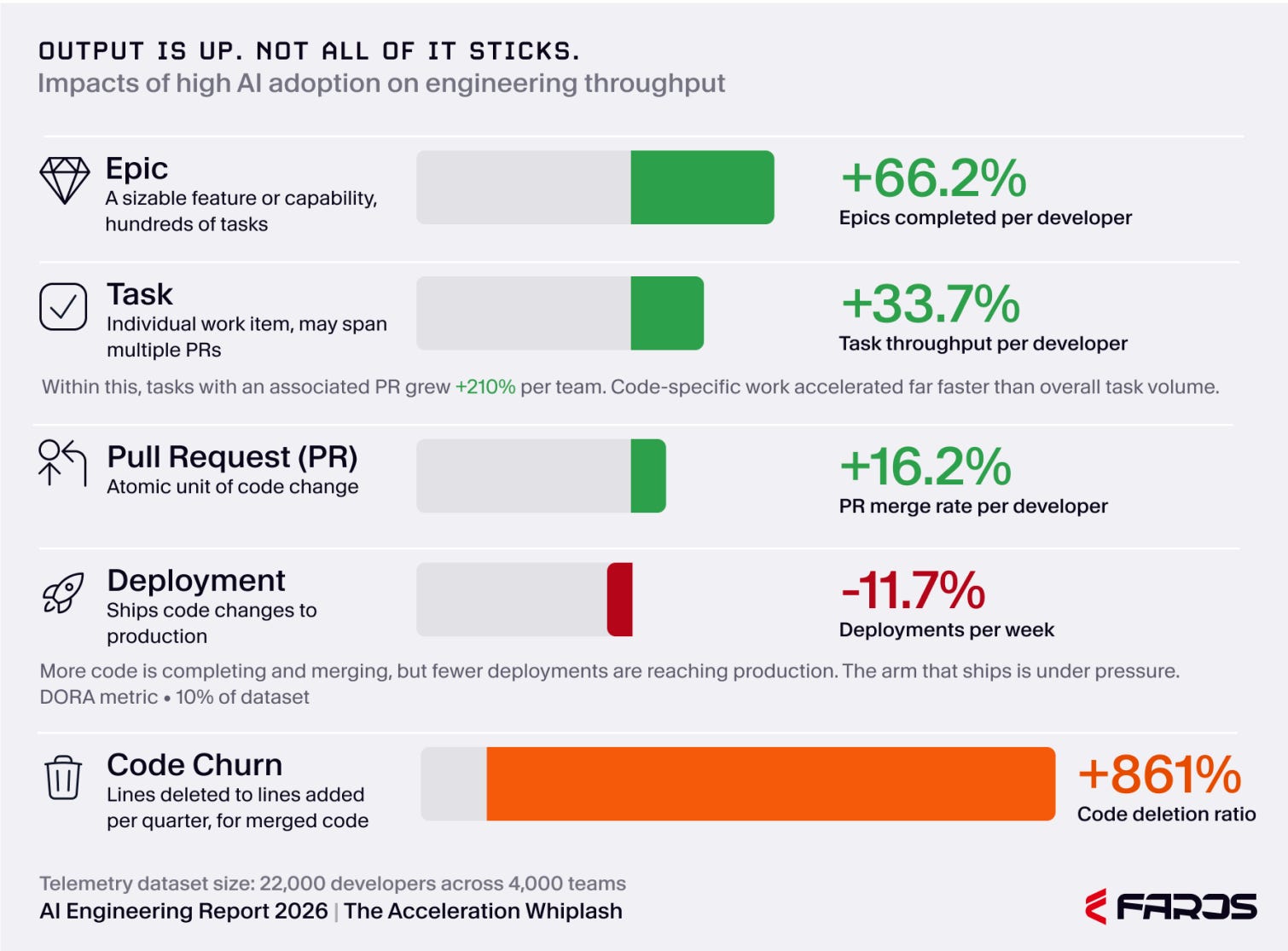
First, AI increased upstream output. Faros reports task throughput per developer up 33.7%, epics completed per developer up 66.2%, PR merge rate per developer up 16.2%, and tasks completed per team with an associated PR up 210%. Those numbers show acceleration, especially around code-related work.
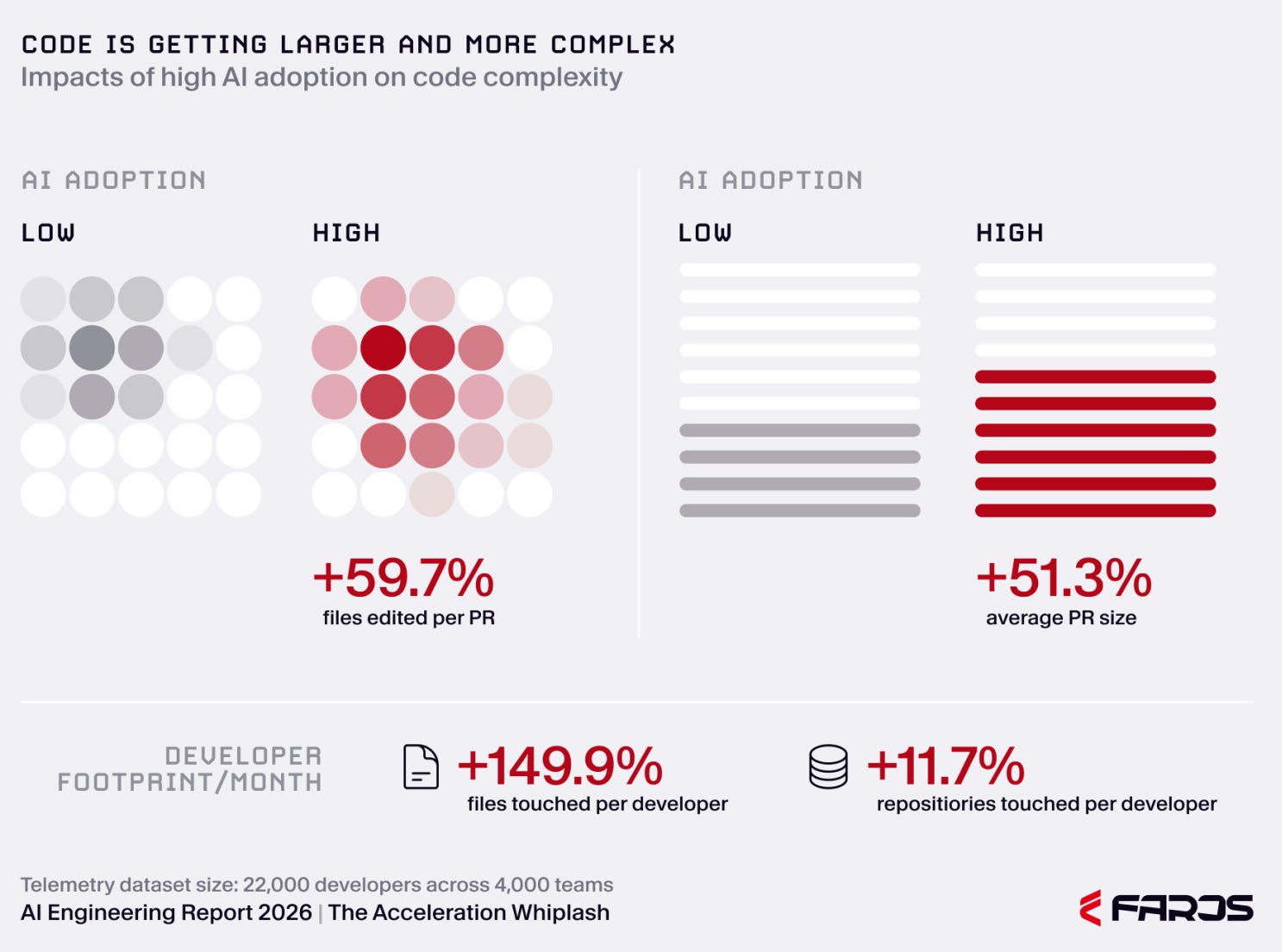
Second, the work became larger and harder to absorb. Faros reports average PR size up 51.3%, average files edited per PR up 59.7%, files touched per developer per month up 149.9%, and repositories touched per developer per month up 11.7%. In plain English, AI-assisted work did not merely arrive faster. It arrived in larger packages, spread across more of the codebase.
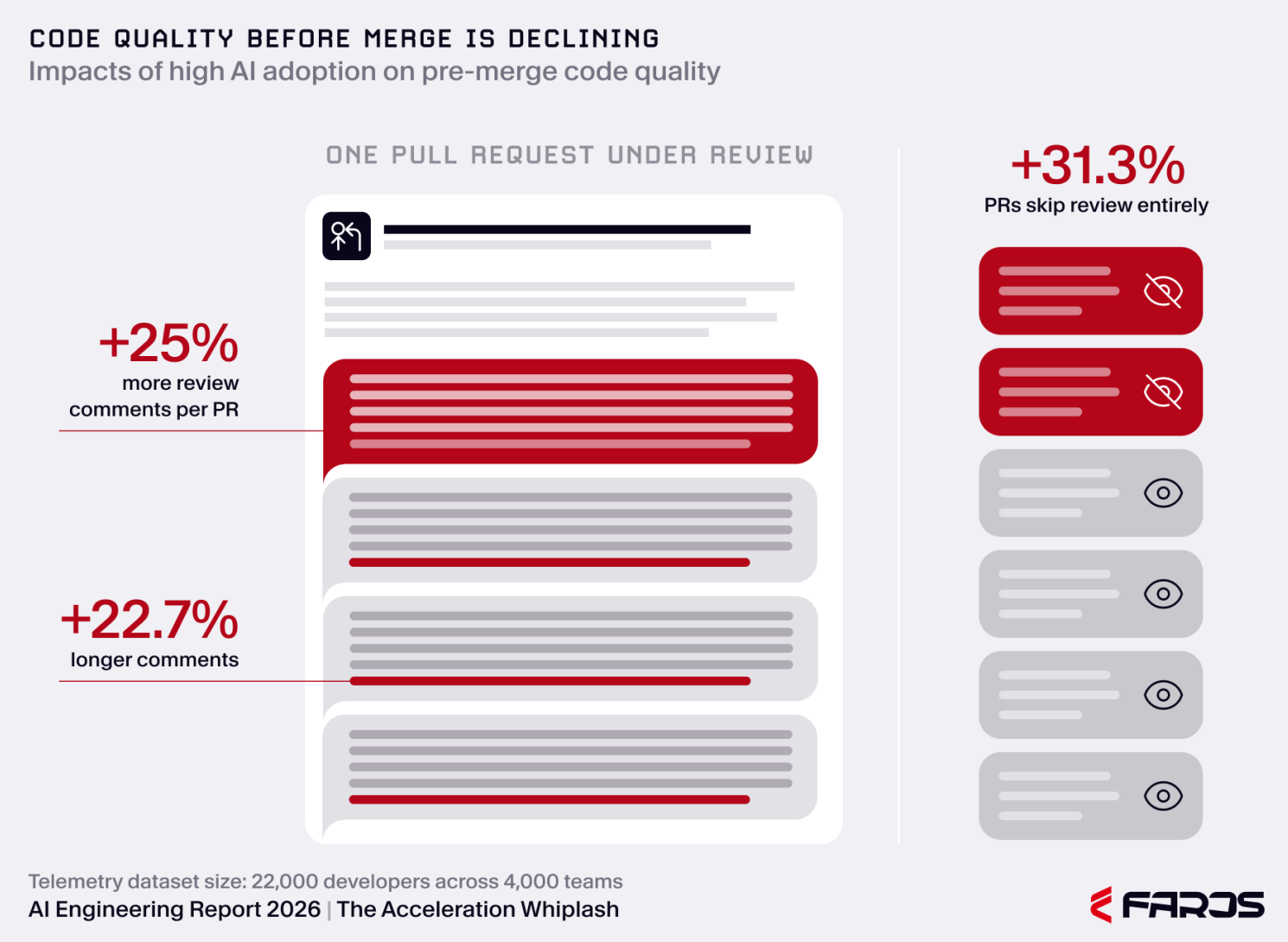
Third, review absorbed the shock. Faros reports review comments per PR up 25%, average review comment length up 22.7%, and PRs merged without any review up 31.3%. The report includes sensible caveats: larger PRs can naturally produce more comments, and AI review agents may inflate comment volume. But the workflow timing data points in the same direction: median time to first PR review increased 156.6%, average time in PR review increased 199.6%, and median time in PR review increased 441.5%.
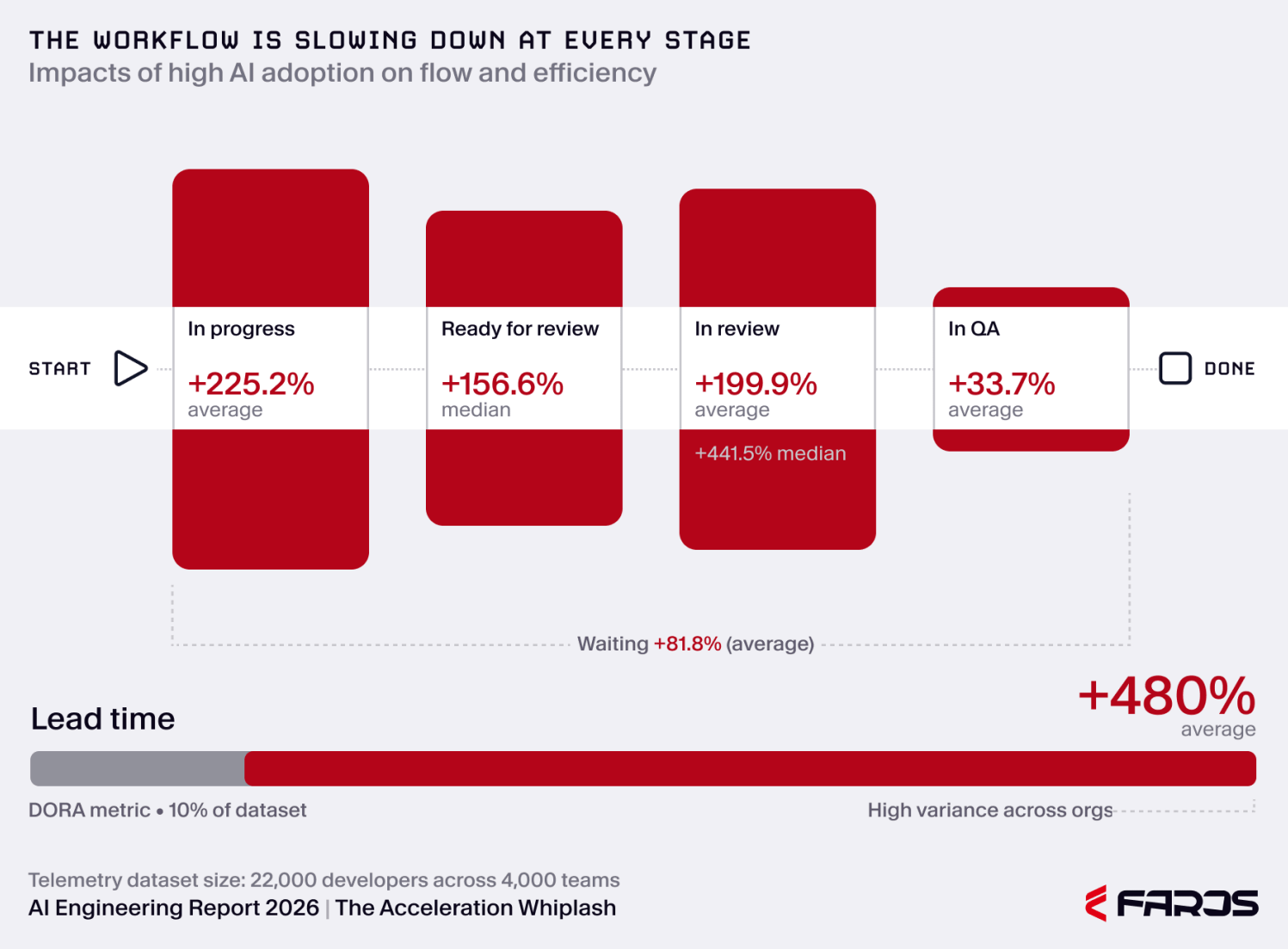
Fourth, the system slowed downstream. Faros reports average time a task spends in progress up 225.2% and average waiting time up 81.8%. For the subset of organizations that instrumented lead time from commit to production, approximately 10% of the dataset, Faros reports lead time up 480.4%. The report itself warns that this figure has high variance and should be treated directionally, but the direction fits the wider pattern: code is completing, but it is not reaching production faster.
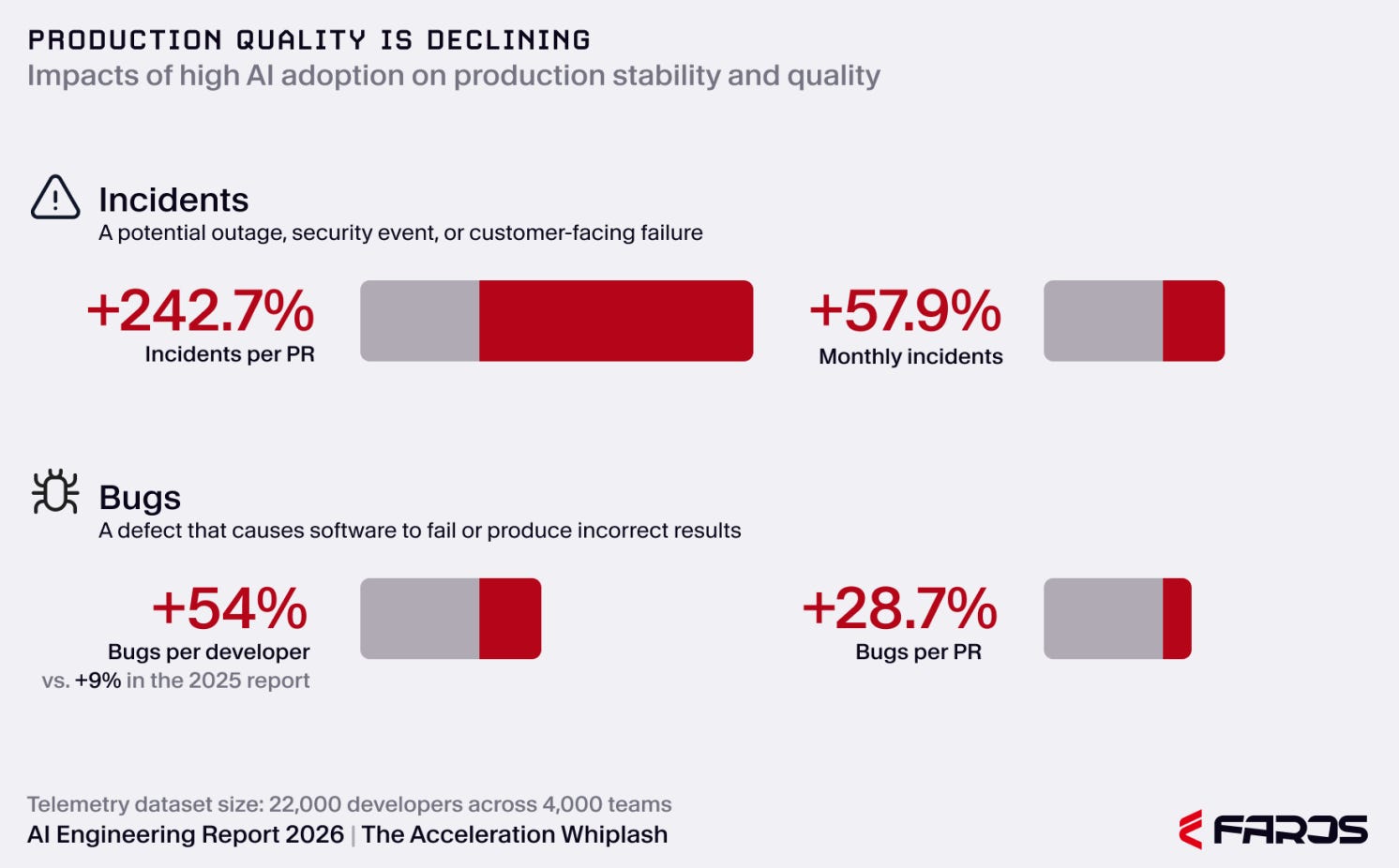
Fifth, production paid the bill. Faros reports incidents per PR up 242.7%, monthly incidents up 57.9%, bugs per developer up 54%, bugs per PR up 28.7%, and reopened Jira tickets up 12.6%. The report is careful about one unresolved question: future analysis should examine whether the increase in bugs and incidents persists after normalizing for PR size, or whether larger PRs explain much of the deterioration. That caveat matters. But even with it, the signal is serious.
The numbers are not the story. The movement of pressure is the story.
Loopy diagram: AI acceleration whiplash
This first Loopy model shows two connected vicious cycles. More AI-assisted coding creates more PR volume. More PR volume increases review load. High review load creates delivery pressure, which often pushes teams to use AI even more aggressively. At the same time, heavy review load reduces review quality, defects escape, and rework comes back as more PR volume.
The pass fills up, so the kitchen tries to chop faster.
Faros does not prove that AI mechanically causes every downstream failure in every organization. It shows a telemetry pattern that systems thinkers should take seriously: as AI adoption rises, upstream output rises, and several downstream absorption and quality signals worsen.
That is enough to ask a better question.
Not: is AI making developers faster?
The better question is: where is the system actually constrained?
This is not a contradiction. It is suboptimization
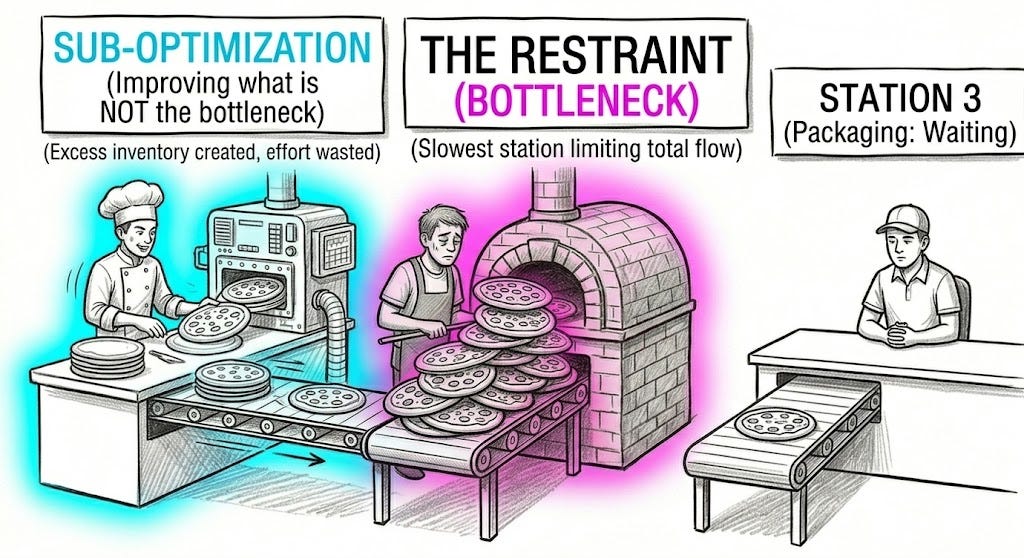
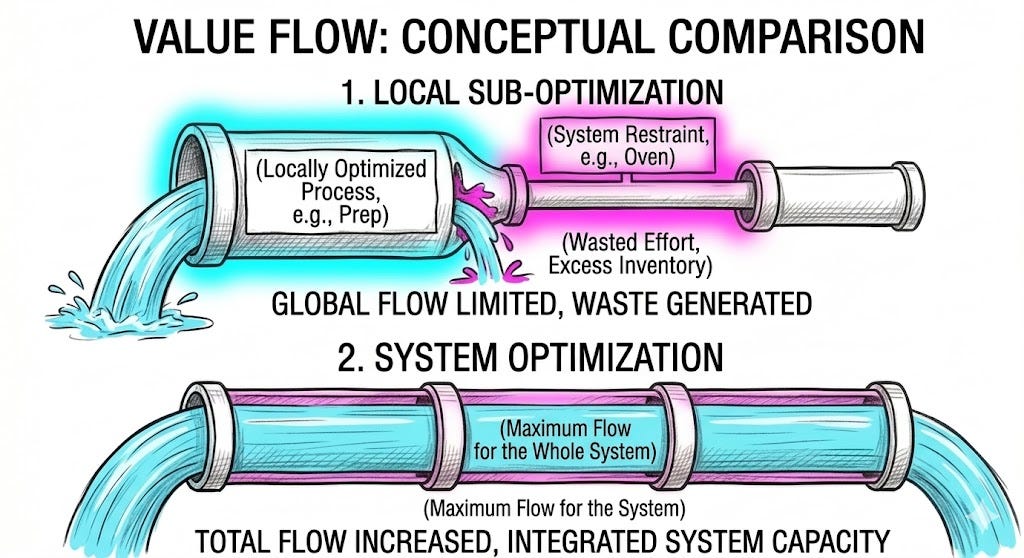
Suboptimization happens when a part of the system improves in a way that does not improve the whole. Sometimes it merely fails to help. Sometimes it actively makes the system worse by increasing pressure on the true constraint.
This is why the AI productivity debate can feel contradictory. Developers can feel faster because the local act of writing, editing, and exploring code has become easier. Managers can see more tasks completed because local output has increased. Yet reviewers can be drowning, QA can be slower, production can be less stable, and customers can see more defects.
All of those things can be true at the same time.
DORA’s recent findings help explain part of the tension. The 2025 DORA report frames AI as an amplifier: it magnifies an organization’s existing strengths and weaknesses, and the strongest returns come from improving the underlying organizational system, not from the tools alone. That is a systems claim, not a tooling claim.
This is also where Faros and DORA diverge. DORA frames AI as an amplifier of organizational strengths and weaknesses, while Faros reports that even organizations with strong pre-AI engineering performance, mature DevOps practices, high DORA scores, and disciplined delivery processes were not insulated from downstream deterioration. These claims are not necessarily incompatible. A strong system can still be overloaded if one station accelerates faster than the constraint can adapt.
DORA’s 2024 research also warned that AI adoption had tradeoffs. Google’s DORA summary states that a 25% increase in AI adoption was associated with an estimated 1.5% decrease in delivery throughput and a 7.2% decrease in delivery stability, while still reporting improvements to parts of the development process. The important lesson is not that AI is harmful by default. The lesson is that improving development activity does not automatically improve software delivery performance.
That sentence should make engineering leaders pause.
Software delivery is not a typing contest. It is a constraint-governed system. If we optimize the non-constraint, we may only produce more pressure for the constraint to absorb.
The kitchen did not fail because the chopping machine was bad. It failed because the restaurant treated faster chopping as faster dinner.
Strong foundations are not immunity
This is where the Faros takeaways become uncomfortable.
DORA 2025 frames AI as an amplifier: organizations with stronger systems should be better positioned to benefit from AI and avoid some of its downsides. That is a reasonable hypothesis. Good tests, CI/CD, observability, small batches, and disciplined delivery should matter.
Faros’ telemetry adds a harsher correction. Its tenth-takeaways article says high-performing engineering organizations, including those with mature DevOps practices, high DORA metrics, and disciplined delivery processes, experienced the same downstream deterioration as everyone else.
Strong foundations do not repeal system dynamics.
They increase capacity. They improve feedback. They make problems easier to see. But they do not create infinite absorption. If AI increases the arrival rate of work faster than review, testing, deployment, and production learning can absorb it, even a mature system can overload.
This is not a contradiction between DORA and Faros as much as a difference in lens. Survey data can capture perceived productivity, confidence, and adoption. Telemetry can reveal what happens later in the system: queues, rework, incidents, unreviewed merges, and bugs reaching customers. Faros makes that distinction explicitly when contrasting survey perception with engineering-system telemetry.
The lesson is not “foundations do not matter”. They matter enormously. The lesson is sharper: foundations are not armor. They are capacity. And capacity can be exceeded.
Maturity is not immunity. It is capacity under conditions.
A system that was healthy at one arrival rate can become fragile at another.

Code generation was not the constraint
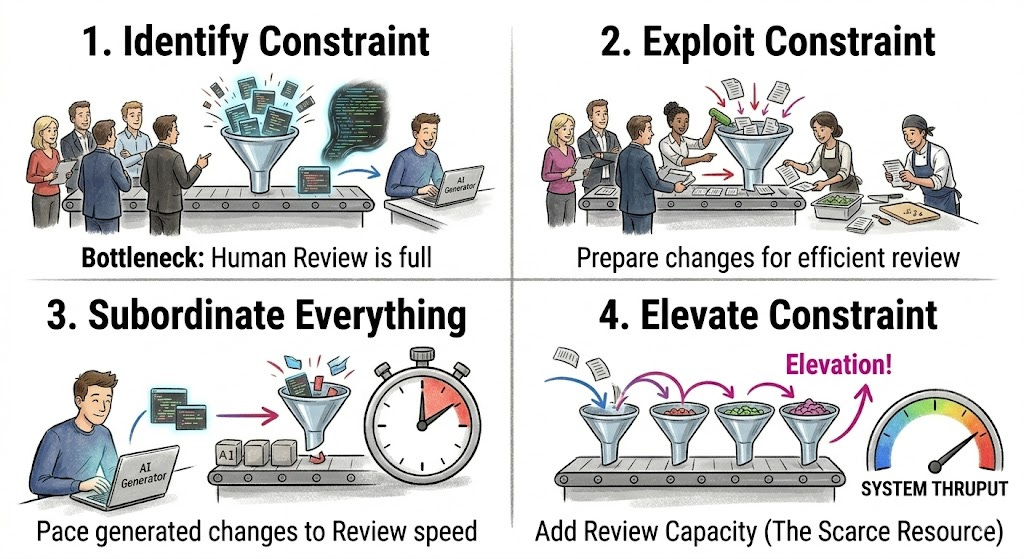
Theory of Constraints (TOC) starts with a hard question: what limits the system from achieving more of its goal right now?
The classic five focusing steps are:
Identify the system constraint.
Exploit the constraint using what already exists.
Subordinate everything else to the constraint.
Elevate the constraint if it still limits the system.
Repeat when the constraint moves, and avoid inertia.
TOC is explicit about the managerial move: identify the system constraint and improve that constraint, rather than optimizing every resource independently.
That is exactly the risk with AI-generated code.
It doesn’t matter how your workflow would look like
Option 1:

Option 2:

Option 3:

The review step is where many AI strategies fail. Subordination means that non-constraints should not run at maximum local efficiency. They should run in a way that supports the constraint. A non-bottleneck producing at full speed may look efficient on its own dashboard while damaging the whole system.
That is exactly the risk with AI-generated code.
If review is the constraint, increasing code generation mainly increases the review queue. If production stability is the constraint, increasing merged changes mainly increases risk exposure. If architectural understanding is the constraint, AI can help produce plausible changes faster than the organization can reason about their consequences.
The bottleneck does not care who wrote the code.
In TOC terms, a lot of AI-generated code is not throughput. It is inventory.
A pull request is not value. It is a claim on future judgment.
AI fed the bottleneck
Once we look through TOC, the Faros data becomes easier to interpret.
AI made it cheaper to start work. Developers touched more PRs per day, switched across more task contexts, restarted more work, and left more in-progress tasks inactive for seven or more days. Faros reports daily PR contexts per developer up 67.4%, daily task contexts up 17.7%, work restarts up 13.8%, and in-progress tasks with no PR or activity in the previous seven days up 26%.
That is not just “more activity”. It is a system where starting has become cheaper than finishing.
The pass in the restaurant fills up. The head chef now has to inspect more plates, with more ingredients, prepared faster, by a machine that does not know which orders were misunderstood. Some plates are fine. Some are almost fine. Some look fine until the first customer takes a bite.
Faros describes AI-generated code as often superficially convincing: idiomatic, well-named, and stylistically consistent with the surrounding codebase. The failures, when present, may be structural or logical, which means reviewers must reason about intent, not just scan for obvious mistakes. Faros calls this slow, expensive cognitive work, and says it falls heavily on senior engineers.
That is how the bottleneck gets fed.

Review is not a cleaning service for generated code. It is a scarce decision point in the system.
When generated work arrives too broad, too large, too under-tested, or too detached from intent, review becomes the warehouse where upstream quality problems are stored. A gate only works when the gatekeeper is not buried.
The wrong response is to say: “Add more review.”
More review may be needed temporarily, but it treats the symptom. If the code arriving at review is not review-ready, the deeper problem is upstream. The authoring process is sending work to the constraint before the work deserves constraint attention.
AI did not merely increase output. It changed the shape of the queue.

The system pushed back
Donella Meadows gives us the language to explain why this keeps surprising us. In Thinking in Systems, she explains that a system is made of interrelated things that produce a characteristic pattern of behavior over time. She also argues that systems often generate their own behavior through their structure, rather than simply reacting in linear ways to external events.
That is why “AI writes code faster” is an incomplete statement. It tells us something about one element. It tells us much less about the interrelations.
What happens to review queues? What happens to QA? What happens to deployment frequency? What happens to incident response? What happens to senior engineers who now spend more time reconstructing the intent behind plausible code? What happens to the codebase after six months of larger PRs touching more files?
Meadows also argues that words are often insufficient for systems because prose unfolds linearly, while systems act in many directions at once. That is why Loopy diagrams matter here. They help show that AI is not pushing on one isolated lever. It is changing arrival rates, feedback loops, queues, and delays.

The system pushes back through delay. Feedback arrives later. Wrong work survives longer. Rework consumes the same people needed for review. The organization becomes busier, but not necessarily more effective.
Little’s Law gives this intuition a mathematical backbone. In queueing theory, the long-term average number of items in a stable system equals the average arrival rate multiplied by the average time an item spends in the system. Expressed as L = λW, it is not a perfect model of messy software organizations, but it gives a useful warning: if more work enters a constrained system and exit capacity does not rise with it, WIP or waiting time tends to grow. ([Wikipedia][6])
That is the Faros pattern in systems language.
AI increased arrival rate. The downstream system did not absorb it cleanly. WIP, waiting, review time, rework, and production quality signals moved in the wrong direction.
Starting work is local. Finishing work is systemic.
The scarce resource is judgment
For years, many organizations behaved as if the bottleneck in software delivery was typing. Developers were expensive, code took time, and the visible work was the writing of software. So when AI made code cheaper to generate, the conclusion seemed obvious: now we can do more.
But software was rarely constrained by typing.
The scarce resource was usually judgment: deciding what matters, understanding the system, preserving design options, validating behavior, reviewing risk, operating safely, and learning from production. AI changes the economics of code generation, but it does not remove the economics of comprehension.
Judgment is knowing when the generated solution solves the wrong problem. It is knowing when code fits the syntax of the architecture but violates the model. It is knowing whether a test protects behavior or merely freezes implementation. It is knowing when a small-looking change has a large blast radius. It is knowing when the AI has produced something plausible enough to pass a shallow review, but wrong enough to damage the system later.
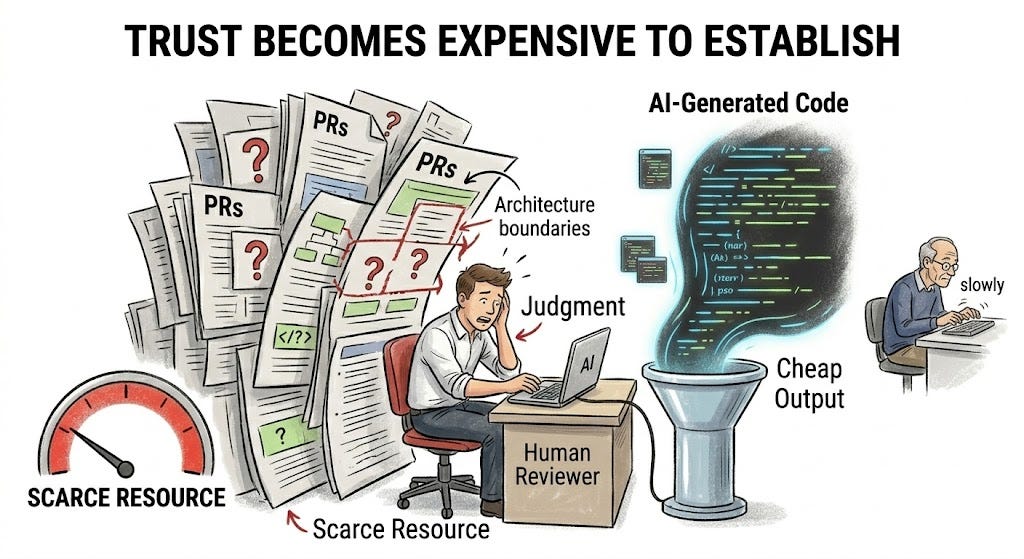
The bottleneck is not review as a calendar event. It is the scarce ability to decide whether a change is correct, valuable, safe, reversible, and coherent with the system we intend to preserve.
This is why trust becomes the new bottleneck.
Trust is not a mood. Trust is an operational property. A change becomes trustworthy when it is small enough to understand, specified enough to test, aligned enough with architecture, safe enough to deploy, observable enough to monitor, and reversible enough to recover from.
When code becomes cheap to generate, trust becomes expensive to establish.
That is why the next generation of engineering performance will not be defined by who generates the most code. It will be defined by who can create the highest rate of trustworthy change.
Cheap code is not a cheap asset
Cheap code is not automatically cheap software.
Cheap code can still create expensive obligations.
Software economics forces us to look beyond the cost of creation. A change has a build cost, but it also has basal cost, carrying cost, future change cost, cost of delay, risk, optionality, and cognitive load. AI may reduce part of the build cost while increasing several of the others.
It may also create a new coordination cost: the cost of managing the AI system itself.
A useful conceptual model is:
Real cost ≈ build cost
+ basal cost
+ carrying cost
+ future change cost
+ rework cost
+ incident cost
+ cost of delay
+ AI supervision costThis is not an accounting equation. It is a discipline for not lying to ourselves.
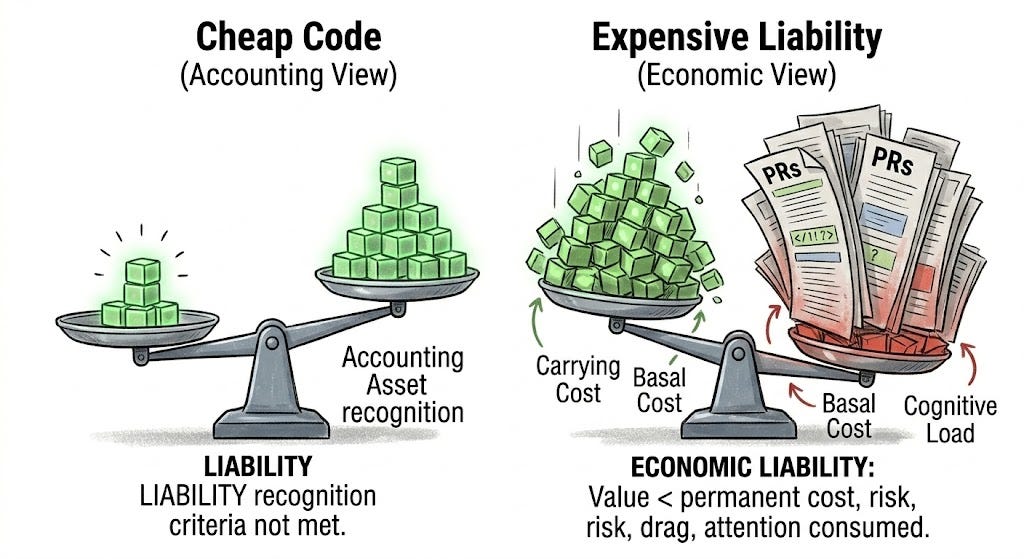
This matters because accounting and economics do not ask exactly the same question. In accounting terms, some software can be treated as an intangible asset when it meets the relevant recognition criteria. IAS 38 states that when software is not an integral part of the related hardware, computer software is treated as an intangible asset. FASB also has guidance for software costs that fall under internal-use software accounting.
But this article is not making an accounting claim. It is making an economic one.
Software starts as an economic liability, not an asset, until it proves that the value it creates exceeds the cost, risk, and attention it permanently consumes.
Every line that enters the product consumes future attention. It must be read, tested, secured, operated, debugged, migrated, deleted, or understood by someone later. It occupies cognitive space. It increases the surface area of change. It creates obligations for people who were not present when it was written.
Software becomes an economic asset only when the capability it creates is worth more than the permanent cost of carrying it. Until then, it is not value. It is a claim on future money, time, attention, and judgment.
Loopy diagram: Software liability loop
This second Loopy model shows the economic vicious cycle. More generated code increases software liability. More liability increases carrying cost. Carrying cost increases cognitive load. Cognitive load slows future change. Slower future change creates delivery pressure. Delivery pressure pushes the team to generate even more code.
The organization tries to escape the cost of software by producing more software.
This is why AI-generated code can be economically dangerous even when it is locally cheap. It reduces the cost of producing the liability, but not necessarily the cost of carrying it. If AI helps create more code than the organization can understand, validate, operate, and evolve, it has not created assets faster. It has created liabilities faster.
The Faros data points toward this cost migration. Larger PRs increase blast radius. More files touched per PR increase reasoning cost. More review time increases senior engineering load. More incidents increase operating expense. More reopened tickets signal rework. More code churn raises the question of whether shipped code is surviving long enough to justify the celebration.
The economic question is not whether AI makes code cheaper to produce.
The economic question is whether AI makes valuable change cheaper to absorb.

What leaders should measure now
A metric system that celebrates generated code will reward congestion. A metric system that celebrates accepted suggestions will reward trust without evidence. A metric system that celebrates closed tickets without downstream signals will confuse output with outcome.
A better measurement system begins with four questions.
First: is value flowing?
Measure lead time from idea to production, lead time from commit to production, deployment frequency, customer-visible outcomes, and whether completed work actually reaches users. Faros reports that PR merge rate rose 16.2%, but deployments per week declined 11.7% in the measured subset. That is the shape of a system where local completion and production flow diverge.
Second: where is work accumulating?
Measure WIP, open PRs, stale tasks, waiting states, review queues, blocked items, and merged-but-unreleased work. If AI increases the rate of starting work faster than the system can finish it, WIP becomes the shadow inventory of the organization.
Third: what is coming back?
Measure rework, reopened tickets, recent code deletion, bugs per PR, incidents per PR, escaped defects, change failure rate, failed deployment recovery time, and deployment rework rate. Work that returns is not merely a quality problem. It is evidence that the system accepted something before it was ready.
Fourth: who is absorbing the cost?
Measure senior review load, context switching, interruptions, daily PR contexts, daily task contexts, and time spent reconstructing intent. If AI shifts cost from generation to review, the burden often lands on the people with the deepest system knowledge. That is dangerous because those people are also needed for architecture, mentoring, incident response, and the decisions that protect future optionality.
Fifth: are the foundations still absorbing the new load?
Measure whether the practices that used to protect the system still work under AI-accelerated volume: review latency, test signal quality, flaky test rate, CI queue time, deployment stability, rollback frequency, escaped defects, and incident clustering after AI-heavy changes. A practice that worked at human-paced throughput may fail when the arrival rate changes.
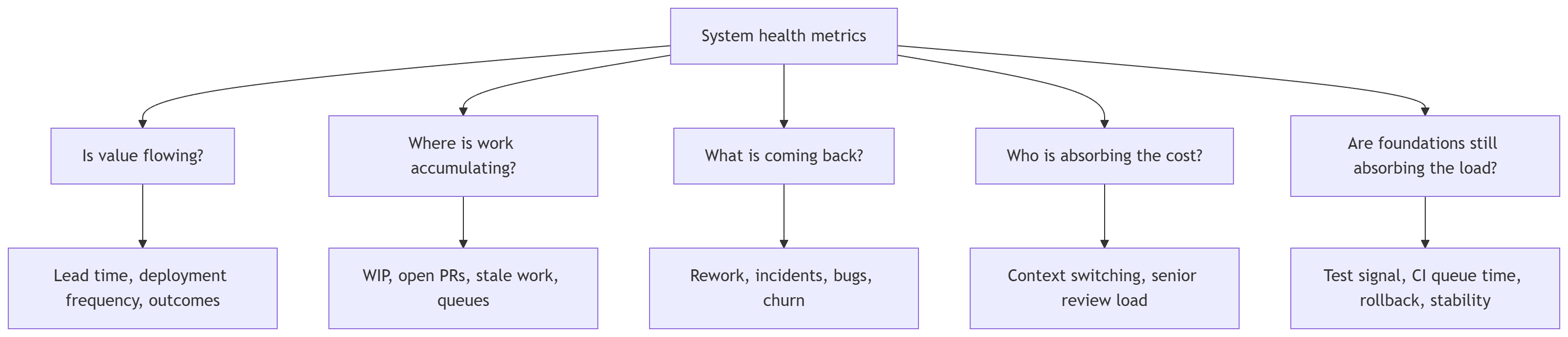
Also measure context debt. If the same questions appear in review again and again, if agents repeatedly miss architectural boundaries, if tests are unclear, or if engineers must reconstruct intent from scratch, the problem is not only the generated code. The system is missing usable context. That missing context becomes review cost.
Also measure AI supervision cost: the time spent maintaining prompts, rules, context files, agent instructions, review scaffolding, corrective workflows, and quality gates that exist only because the tool cannot yet manage the work reliably by itself.
These metrics are not a new altar. They are instruments. Their job is to reveal the constraint.
Once the constraint is visible, the organization can decide whether AI is protecting it, exploiting it, elevating it, or flooding it.
How to use AI without flooding the system
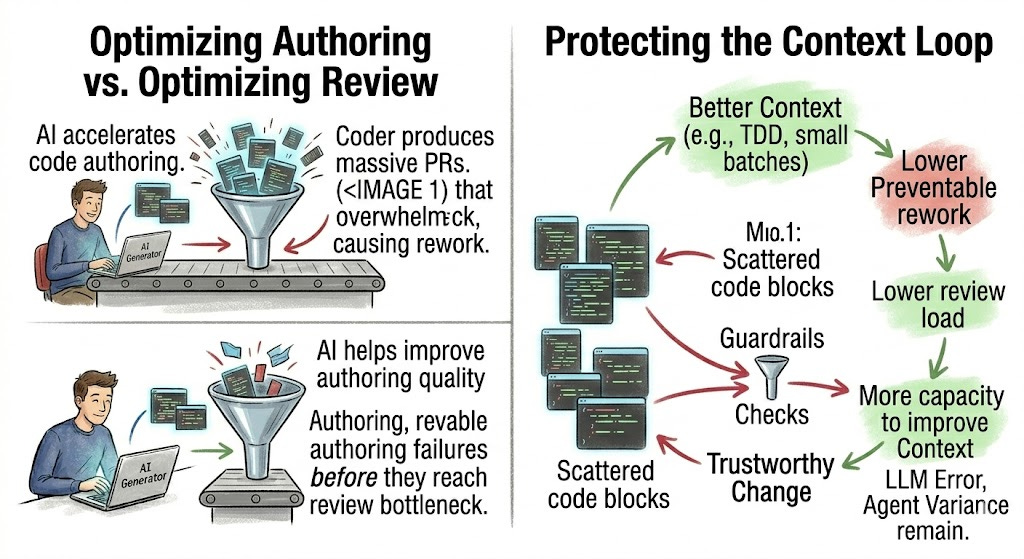
The worst response to this data is panic. The second worst is blind acceleration.
AI should not be banned from software delivery. It should be subordinated to the system’s constraint. That is the practical center of the argument.
AI is not the drum. The constraint is the drum. AI must follow the beat.
That changes how leaders should govern AI-assisted development. The question is no longer “How do we get more developers to use AI?” The question becomes “Where should AI operate so that the system constraint improves rather than drowns?”
Start by identifying the constraint. Look at where work waits, where quality escapes, where decisions queue, and where senior judgment is overloaded. If the constraint is review, use AI to improve authoring quality, prepare review context, generate risk summaries, and keep PRs small. Do not use it to spray larger PRs into an already overloaded queue.
There is one loop leaders should protect deliberately: the context loop. But we should be careful about what that loop can and cannot do.
AI-assisted work is only as good as the environment it works inside. Architecture decisions, testing conventions, domain language, coding standards, previous incidents, examples of good changes, and explicit boundaries are not documentation for later. They are part of the authoring system now.
Better context can reduce preventable mistakes. It can make the agent less blind. It can reduce some review pain. It can make repeated errors easier to turn into reusable rules, examples, tests, or constraints.
But there is a cost here that the industry often hides.
Context management is not free. Every architecture note, agent instruction, coding rule, example, test convention, memory file, prompt template, and workflow constraint has to be written, maintained, reviewed, updated, and kept aligned with the real system. When the tool does not manage this well, the burden moves to the team.
This is not a small detail. It means engineers spend time managing the tool instead of improving the product. They maintain prompts, rules, context files, agent workflows, retrieval hints, and guardrails because the tool is not reliable enough to carry the work by itself. The team becomes responsible not only for the software, but also for the scaffolding required to make the AI behave acceptably.
This is an opinionated economic reading, not a measured claim from the Faros report.
It is time away from the core business. It is attention diverted from product learning, architecture, customer problems, operations, and delivery. And because the context is never finished, the cost is not a one-time setup cost. It becomes carrying cost.
The tool promised leverage. But part of the leverage is paid back as supervision.
This is why context engineering should not be treated as free infrastructure. If an organization needs to constantly chase, correct, constrain, and feed the tool so that it produces acceptable work, then the tool is not only reducing cost. It is also creating a new operating expense.
But context is not magic.
Context reduces some mistakes. It does not remove the need for judgment.
Even with strong context, LLMs will still make mistakes. Context windows are limited. Retrieval can miss relevant information. Different CLIs and agents manage context differently. Some will preserve intent better than others. Some will drift, truncate, overfit to the wrong files, or produce plausible code that still needs human review.
So the goal is not blind trust. The goal is lower preventable rework.
Poor context creates more preventable mistakes. More mistakes increase review pain. More review pain leaves less capacity to maintain useful context. The loop degrades quietly.
The opposite is possible too. Better context reduces preventable mistakes. Less preventable rework lowers review pain. Lower review pain leaves more capacity to maintain context. But residual rework remains, because human judgment remains part of the system.
Alfredo Artiles describes a similar reinforcing documentation loop: when documentation becomes obsolete, trust in it falls, usage falls, and the motivation to keep it updated falls too. If documentation becomes useful and accessible, use increases and the habit of maintaining it becomes easier to sustain. The same structure applies to AI context, with one important difference: better context can reduce preventable mistakes, but it does not remove LLM error.
Better context can reduce preventable mistakes, but agent variance and residual rework remain. Human judgment is still required.
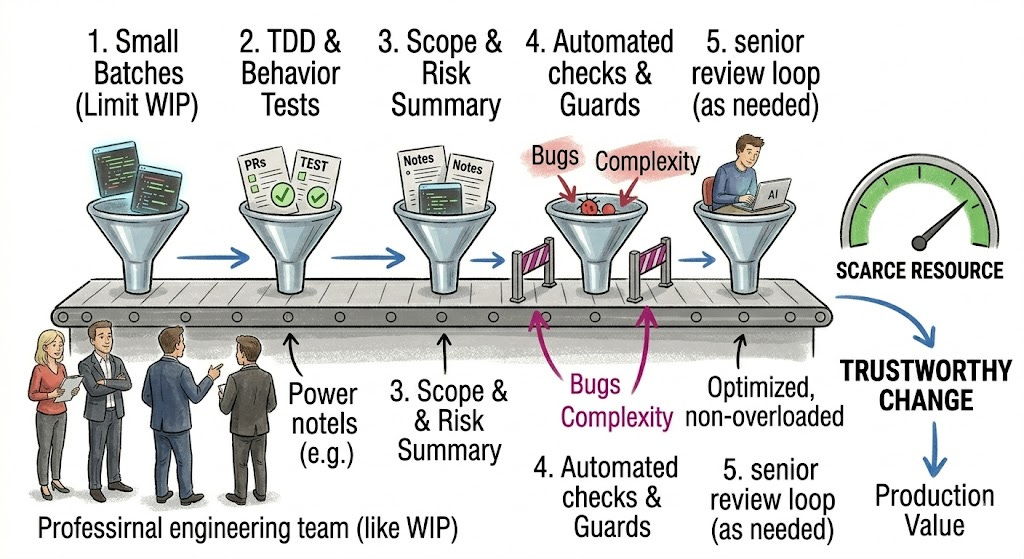
Then protect the constraint from bad inputs. Generated code should not arrive at review without tests, context, scope explanation, risk notes, and evidence that basic checks have passed. If Test-Driven Development (TDD) is appropriate for the work, AI should help create behavior-focused tests before or during implementation, not merely produce implementation and ask humans to clean up afterward.
Next, limit batch size. AI does not feel review cost. Humans do. Production does. Customers do. Small batches protect flow, review precision, rollback, and learning. If an agent produces broad changes across many files or repositories, the default response should not be admiration. It should be suspicion until the scope is justified.
Then turn human review into system learning. Every serious human review comment should feed back into coding guidelines, architectural rules, prompt context, test strategy, or automated checks. If the same review comment appears repeatedly, the system is paying recurring operating expense for a preventable upstream failure.
Finally, use AI where it strengthens the constraint. AI can help search incident history before implementation. It can draft characterization tests before refactoring. It can summarize architectural decisions. It can detect risky PRs. It can prepare rollback plans. It can find stale WIP. It can identify repeated review comments. It can help reduce the cost of doing the disciplined thing.
That is very different from using AI to maximize code volume.
Stop measuring AI success by accepted suggestions. Stop celebrating PR volume without checking downstream flow. Stop letting agents create broad changes without explicit scope limits. Stop sending untested generated code to senior engineers as if review were a laundry service. Stop treating incidents as a production problem when many of them were authored upstream.
Do this instead: before scaling AI, find the constraint. Then ask whether AI will protect it, elevate it, or flood it.
If the answer is flood it, redesign the system before you celebrate the speed.
Conclusions: AI is not the drum
The next phase of AI adoption will not be won by the organizations that generate the most code. It will be won by the organizations that know where value actually gets stuck.
It will also not be won by organizations that assume yesterday’s engineering maturity automatically protects tomorrow’s AI-accelerated system.
That is the central lesson from joining the Faros data with systems thinking, Theory of Constraints (TOC), Loopy-style causal loops, and software economics. Faros shows real acceleration and real downstream degradation. DORA reminds us that AI acts through the organizational system, not outside it. METR reminds us that perceived speed and measured performance can diverge. TOC gives us the discipline to ask where the constraint is. Meadows gives us the humility to remember that systems push back through feedback loops, delays, and interrelations.
AI is not the villain. The villain is local optimization dressed up as transformation.
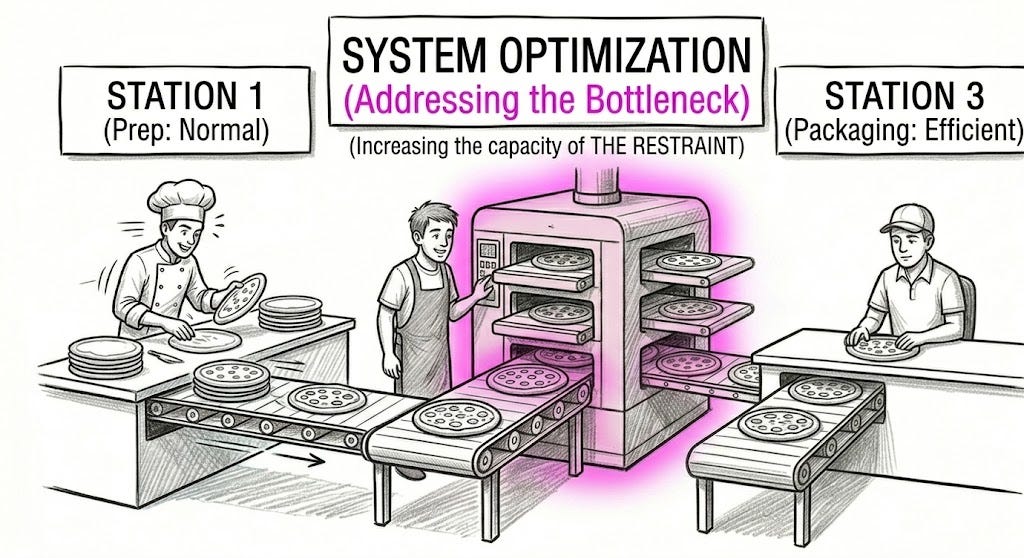
We made code faster. That can be useful. But if the system cannot absorb, validate, operate, and evolve that code, we have not accelerated asset creation. We have accelerated liability creation.
The organizations that benefit most from AI will not be the ones with the most prompts. They will be the ones with the best mechanisms for reducing preventable rework while preserving human judgment.
Maturity is not immunity. It is capacity under conditions.
When the conditions change, the constraint must be found again.
The kitchen does not need the chopping machine to slow down. It needs the kitchen to stop pretending that chopping is dinner.
AI is not the drum.
The constraint is.
And when judgment becomes the constraint, flooding it is not acceleration. It is the productivity trap.
References
Faros Research. AI Engineering Report 2026: The Acceleration Whiplash. https://www.faros.ai/research/ai-acceleration-whiplash
Faros Research. Ten takeaways from the AI Engineering Report 2026: The Acceleration Whiplash. https://www.faros.ai/blog/ai-acceleration-whiplash-takeaways
Meadows, Donella. Thinking in Systems: A Primer. Chelsea Green Publishing, 2008. https://www.chelseagreen.com/product/thinking-in-systems/
Goldratt, Eliyahu M. The Goal: A Process of Ongoing Improvement. North River Press, 1984.
Goldratt, Eliyahu M. The Haystack Syndrome: Sifting Information out of the Data Ocean. North River Press, 1990.
LeanProduction. Theory of Constraints. https://www.leanproduction.com/theory-of-constraints/
Theory of Constraints Institute. Five Focusing Steps, a Process of On-Going Improvement. https://www.tocinstitute.org/five-focusing-steps.html
DORA. State of AI-assisted Software Development 2025. https://dora.dev/dora-report-2025/
Google Cloud. Announcing the 2024 DORA report. https://cloud.google.com/blog/products/devops-sre/announcing-the-2024-dora-report
Google Cloud. Impact of Generative AI in Software Development. https://dora.dev/ai/gen-ai-report/
Becker, Joel, Rush, Nate, Barnes, Elizabeth, Rein, David. Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity. https://metr.org/blog/2025-07-10-early-2025-ai-experienced-os-dev-study/
Peng, Sida, Kalliamvakou, Eirini, Cihon, Peter, Demirer, Mert. The Impact of AI on Developer Productivity: Evidence from GitHub Copilot. https://arxiv.org/abs/2302.06590
Little, John D. C. A Proof for the Queuing Formula: L = λW. Operations Research, 1961. https://ideas.repec.org/a/inm/oropre/v9y1961i3p383-387.html
IFRS Foundation. IAS 38 Intangible Assets. https://www.ifrs.org/issued-standards/list-of-standards/ias-38-intangible-assets/
Financial Accounting Standards Board. Accounting for and Disclosure of Software Costs. https://www.fasb.org/page/PageContent?pageId=/projects/recently-completed-projects/accounting-for-and-disclosure-of-software-costs.html
Artiles, Alfredo. Systems Thinking Radar, Vol. 2.
